in 5D with multiverse and timetravel
This article is a journal for these projects: github.com/euwbah/dissonance-wasm & github.com/euwbah/n-edo-lattice-visualiser
# tl;dr
A new algorithm for modelling the perception of complexity and tonicity of chords up to 8 notes. Tonicity is the measure of how likely the note is to be perceived as the "tonic", which may or may not correspond to the chord. This is done in real-time which, when used in conjunction with my visualizer, updates a model of pitch memory that tracks the listener's interpretation of up to 8 unique notes over time.
This model is not biased towards any tuning system or musical culture, in the sense that there was no hard-coding of weights/penalties/points from existing musical patterns/vocabulary I am familiar with. Its only inputs are frequencies and the tonicity of each note from the previous update tick. The core model has no machine-learned/statistically regressed parameters and every step is explainable in terms of the frequencies between pairs of notes. Despite this, the results mostly agree with my subjective perception of consonance and root perception in Western/European musical harmony, more than any other model I have seen (however, this is by definition, subjective, but I just needed a model that I can agree with for my personal use).
The only assumption made is that the instrument has a harmonic timbre (although this setting can be changed easily by modifying dyad_lookup.rs).
The model is only based on dyadic relationships between notes, but unlike most other chord complexity models with dyadic-based approaches, it:
- Captures the gestalt of the chord at different hierarchies of detail, without having to precompute the space of -note chord combinations
- Does not have harmonic duality (major and minor triads do not have the same complexity score)
- Depends on the current musical context by keeping track of pitch memory over time
Two key ideas that make it work:
- Modelling subjective interpretations of chords as trees, where a (parent, child) edge is used to model the listener hearing the child note with respect to the parent note, e.g.
C->Emeans E is heard as M3 of C. By aggregating over the space of interpretations, the model considers different permutations of substructures present in the chord that all contribute to the gestalt. (See Interpretation Trees) - Using the asymmetry of the complexity of intervals about the octave to break the symmetry of chord duality/negative harmony. E.g., it is generally accepted that P4 and P5 do not have the same complexity, even though they are octave-duals of each other. This asymmetry is exploited so that intervals have a preferred natural order, and this preference contributes to the likelihood of choosing one interpretation of the chord over another. (See Dyadic Tonicity)
Because it only depends on dyadic relationships, it is computationally efficient and can run in realtime. This model powers the automatic just intonation detemperament, root detection, and dissonance scoring logic in my visualizer which responds as I play.
Example of previous algorithm (less accurate root detection, requires hard coding rules based on circle of fifths which does not work for non-standard tonalities):
Example of new algorithm (more accurate root detection, no hard coding any cultural parameters besides octave equivalence and harmonic timbres):
See more examples on my channel
# Introduction
So far, I haven't found a measure of harmonic complexity/concordance/consonance that agrees with my own subjective perception of chordal and melodic tension and release. I started a bit of initial research towards this goal, and I wanted to document my current progress and thought process in a relatively informal and narrative manner here.
One year ago, I started work on polyadic-old.rs, which is an attempt to compute polyadic chord complexity and do root detection in a way that I am satisfied with. However, the computational cost of the full version of this algorithm is where is the number of notes in a chord, and is the number of candidate ratios that a new tempered note could be relative to the current harmonic context, and I relied a lot on aggressive pruning (via beam-search) to allow this algorithm to run in real-time at as I play, but this aggressive pruning caused the results to deteriorate from the full version quite significantly.
However, in the old algorithm, I found the idea of using spanning trees to represent possible interpretations of a chord promising. This article serves as a journal of my thought process for my second (or third) attempt developing this idea, where complexity is computed as the aggregate complexity over possible interpretation trees.
For context, I needed an algorithm for my real-time detempering music visualizer which heuristically detempers notes played in equal temperament into just intonation (JI) ratios, that is, finding the "most appropriate" JI ratio interval to represent a note that I played which could represent various possible JI ratios. On average, , and so a full search would require around 30 million computations per frame.
I needed a chord evaluation algorithm that can:
Be ridiculously fast. Max 16ms acceptable latency per note played, preferably under 10ms. Each update tick needs to be able to run at least 5 times per second, all while displaying a three.js visualization, OBS screen recording, video streaming, and running VSTs.
Keep track of the current harmonic context and consider the element of time. Since music is contextual, prior notes must be able to affect the current model of concordance and tonality perception, and the root detection/concordance score should evolve over time even as a single chord is held.
- Ideally, rhythmic entrainment and strong/weak beat detection should be added too, but that's an equally huge problem to tackle later on.
Does not have symmetry/negative harmony/duality assumptions. The same chord voicing spelt in upwards intervals (e.g. C E G is a major triad spelt as M3 + m3 up from C) and downwards intervals (e.g., C Ab F being - M3 - m3 down from C) should not necessarily output in the same concordance scores or detected roots.
Perform some sort of root detection. Doesn't have to be perfect (which requires encoding cultural entrainment perfectly), but good enough to detect the root within pm 1 fifths away from the actual root, so that my visualizer can display the correct enharmonic spellings of notes played. E.g., in 31edo, if I play a C major chord with A# approximating , I would rather have the A# displayed as the enharmonic equivalent Bb< (HEWM notation).
Work in any tuning system.
(Not yet implemented) Has proper modelling of the physiology of hearing and psychoacoustic phenomena, e.g., octave non-equivalence (tuning curves), combination/sum-and-difference tones, etc... So far, only a model of lower interval limit is implemented.
(Not yet implemented) A model of cultural entrainment, so that certain harmonic patterns (e.g., 2-5-1s, common licks/riffs/language/vocabulary) that are known to imply a certain tonality/root/mode can be turned off/on in the model.
Except for rhythmic entrainment/beat detection and cultural/vocabulary entrainment models, all of the above features should not be implemented with a black-box machine learning model, but rather a fully explainable and interpretable algorithm that can hopefully give insight into (or at least a description of) the underlying logic (if any) of the harmony derived from the European musical tradition.
If you find any glaring shortcomings in the assumptions, find some part of the algorithm (or its implementation) redundant or incorrect relative to what I claimed it does, if you have a fresh perspective on this problem that can significantly speed up the algorithm, please reach out to me over Discord (@euwbah), Instagram (@euwbah), or email (euwbah [a𝐭] ġmаíḷ [ɗօt] ċοm). I'd very much appreciate and enjoy any discussion on this topic!
I understand that the definition of "tonic", "dissonance", and "root" is very subjective. To help narrow down the scope of my definition, I will identify some musical biases that affects my definition of these words:
Main influences: Romantic, Impressionist, Black American Music & its derivatives (including, but not exhaustively, bebop, swing, great American songbook, R&B, rap, hip-hop, blues, bluegrass, neosoul, ...), and many other contemporaries (Immanuel Wilkins, Soweto Hinkch, Peter Evans, Nick Jozwiak, Micah Thomas, Joel Ross, Jon Elbaz, Guinga, Mid-Air Theif, Brendan Byrnes, Tennyson, Mei Semones, Becca Stevens, Arthur Verocai, ...)
Secondary influences (partial understanding and practice): Renaissance polyphony (mainly Frescobaldi), Bach, Spectralism (mainly all the composers of the Plainsound Music Edition), and Algorave/live-coded music.
Tertiary influences (significant exposure but no formal practice): Early music, Gamelan (especially Balinese), Maqam (especially Taqsim) and Carnatic music.
# Definitions
For the context of this writing,
Consonance is the subjective/cultural perception of pleasantness or stability in musical intervals. It can be influenced by context, culture, and individual listener preferences. When I refer to "consonance", I mean my own subjective interpretation of what I think is consonant, which this algorithm will try its best to model.
Concordance refers to a numerical heuristic score of the "objective/physiological/psychoacoustical complexity" of a musical interval, i.e., we assume that every human has an innate understanding of "complex" vs "simple" harmonies, and the concordance refers to a model of whatever "simple" is. Specifically, in Harmonic Entropy, the presence of timbral fusion, virtual fundamental, beatlessness, and periodicity buzz are signifiers of psychoacoustical concordance. It is assumed that concordance is a contributing factor to consonance, but not the only one. Additionally, concordance is usually measured with the absence of context/time.
Complexity is more specific than concordance. It usually refers algorithm/math used to compute the concordance score, rather than focusing on the perceptual/modelling aspect. In this document I will use concordance and complexity interchangeably, but I will be referring to mainly the algorithmic aspect, not the attempt at modelling a universal human perception of concordance.
Tonicity is a heuristic measure of "root"-perception in chords — a probability distribution of how likely a given pitch (either perceived in the present as external stimuli, in a listener's short-term memory, as a psychoacoustic phenomenon, or implied by cultural entrainment) will be perceived as the "root" or "tonic" of a chord (not necessarily the lowest note). I note that "root" is not rigorously definable, so I give my working definition below. Tonicity can be calculated for a single chord in stasis (played forever), or over time and in context (a chord progression/song).
The tonicity distribution is an attempt to model my own understanding of Western/European harmony, something I have not yet seen in other literature (this is not a softmax of a convolution kernel over pitch classes/FFT spectra, which I find more common in tonality/key-detection machine learning models). Though, my reading is probably outdated, so if you know of any references/people who share similar ideas, please let me know!
Note
So far, this algo only consider pitches that are currently played or have been played, but psychoacoustic and cultural modelling is not yet implemented.
Root, as in the root of a chord/tonality is a reference pitch that is defined by musical culture and context. To give a more quantifiable definition, a note is more rooted/tonic if it is more likely for other notes in the context to be heard with respect to that note as a baseline. Conversely, a note is less rooted/tonic if it is more likely for it to be heard in relation to other notes as a baseline. Ideally, this should correspond to the "local key" of a song, i.e. a progression iii-vi-ii-V-I in C major would (probably) have C as the root, but in my experience, the melody and rhythmic phrasing can have a stronger influence on root perception than the harmony itself. For the purpose of this document, since I only need root perception to be accurate within fifths of the actual root (i.e., actual root is C but guessing G or F is also acceptable).
- E.g., suppose there are two notes, C and a major third E above it, and suppose this is the first thing you hear in a song. Will you hear C as scale degree 1 and E as the 3rd of C; or will you hear C as scale degree b6 of the tonic E? Whatever note you hear as "1" is the root (it can also be neither, but we will not consider that possibility for simplicity's sake).
# Inspiration & references
# A History of 'Consonance' and 'Dissonance' — James Tenney
Cultural and historical aspects of how the perception/definition of what is "consonant" evolves, tracing specifically the lineage of the European classical tradition.
I also like the YouTube channel Early Music Sources.
# Height or complexity functions (see also: D&D's guide to RTT/Alternative complexities)
A purely mathematical, usually number-theoretic (like lowest common multiple, or sum of prime factors) or norm-based/functional-analytic measure of complexity of a JI ratio . When I first encountered the concept of a height function, some limitations immediately stood out:
No standard generalization to tempered non-JI intervals in . It is possible to use smoothing techniques (e.g., compute up to a certain limit and then interpolate using splines/linear methods), which I have used to some extent in my own implementation. Harmonic entropy (see below) solves the issue using a spreading function.
Any (commutative) generalization to chords of more than 2 notes results in negative intervals having the same complexity score as their positive counterparts. E.g., a 4:5:6 major triad and a 10:12:15 minor triad will score the same if we consider simple generalizations like taking the LCM of the 3 integers in the ratio, or just summing up the norms for each of the 3 intervals between the 3 notes. This doesn't reflect my (possibly subjective) experience of 4:5:6 sounding more simple than 10:12:15 (see A note on complexity and duality/negative harmony)
No direct link to psychoacoustic perception of consonance/dissonance, it measures literally the complexity of a number in itself, which works for the first few primes (modelling periodicity and the critical band Plomp & Levelt's model of concordance), but quickly diverges from human perception for higher primes as human perception cannot perfectly distinguish complex ratios.
# Tonal Consonance and Critical Bandwidth & William Sethares' dissmeasure
See also: Python implementation by endolith.
- No restriction to JI-only intervals. It considers the pure frequency content of two complex tones (i.e., musical notes with harmonic partials) and measuring the "roughness".
- Introduces the idea of "roughness" caused by the interaction of beating partials within the critical band: the gray area of when a beating/warbling sensation frequency is too low frequency to be heard as a pitch, but too high frequency to be heard as beats/rhythm, is claimed to be a major contributor to the perception of dissonance in intervals. This is claimed to model the physiology of the basilar membrane, where two frequencies that are too close together will cause physically overlapping excitation patterns on the membrane, causing the indistinguishability of pitches.
I appreciated that this model ties back to the physiology of hearing, which gives a sense of universality (even though in reality much more experiments are needed to confirm this).
It's also great that this is intrinsically a polyadic model (Sethares' algorithm by default considers partials of each individual note) and works really fast (relatively speaking, is fast compared to whatever will be presented here).
However, the final result is effectively an unordered summation of (min-amplitude-weighted) critical band roughness scores over each pair of (sine) frequencies present in the spectrum, meaning that positive and negative chords still gave almost the same output, only disagreeing after a few decimal places due to some modelling of the lower interval limit curve. To me, that small difference is not sufficient to represent the perceived gap in complexity between major and minor.
- E.g.: Dissonance (Consonant Triads) — Aatish Bhatia, clickable demo diagrams showing that both major and minor triads have the same dissonance score.
# Harmonic Entropy
This addressed several limitations of the above methods:
By reframing the problem as a probabilistic one, this allows inputs which are non-JI intervals, any real-valued cents interval will do — the ear hears the external stimuli of an interval of cents, but accepts detunings (or mishears) with probability where is a spreading function, a probability distribution (e.g., Gaussian, Laplace, etc...) centred at 0 where is the probability of hearing an interval as cents when the actual stimulus is cents. This spreading distribution is the basis of the rest of the approach.
By considering three-note combinations (3HE) instead of dyads, which is done by populating the search space with 2-dimensional points representing the 2 intervals between the 3 notes (as opposed to searching through points on the real line up to some Weil/Tenney height or Farey sequence iteration), this model is able to break the negative-harmony "curse" of using purely dyadic heights. The major
4:5:6and corresponding "negative", minor10:12:15, have vastly different entropy/concordance scores.
I initially implemented a generalized -HE algorithm in Ruby for livecoding in Sonic Pi, but found that any quickly becomes intractable for real-time purposes. Every configuration of intervals need to be considered. If I wanted 3-cent resolution (with intermediate values interpolated) for intervals up to a 1 octave span, that still quickly blows up to 25600000000 pre-computed points for only 5-note chords. There were some heuristic optimizations (e.g., lazily populating lattice points in direction of most entropy, assuming the inverse Fourier transform of the Riemann-zeta analytic continuation of HE was smooth/analytic for arbitrary dimensions), which I tried doing in Ruby, then Java, then Rust (though I lost the most of the projects in a corrupted old SSD, sad...). I did to get it working up to 7-HE, but the optimizations deteriorated the results until they were no longer useful.
Things I really liked about HE:
The probabilistic treatment for modelling the uncertainty of human perception of pitch. This idea of extending to intervals in via probabilistic interpretations/kernel smoothing functions was something I wanted to take further.
It generalized to multiple intervals naturally, considering not just dyadic relationships but the entire gestalt of the chord by mapping chords to points in a higher-dimensional space.
What I didn't like was how quickly computations blew up when increases, and I was desperately looking for alternatives that preserved these two properties I needed in a complexity function, while not requiring populating a huge search space (even after applying threshold cutoffs/interpolations) for 7/8-note chords.
# Statistical/machine learning methods
These are very strong and computationally efficient methods for root/key detection, but only viable for 12edo, as they are trained/fitted for an existing corpus of music.
Some general ideas:
- Training an ML model on a melspectrogram (log frequency scale spectrogram/FFT)
- Using moving average amplitude of pitch classes over time, then fitting the distribution of the amplitudes of pitch classes to a known key profile via multilinear regression, machine learning, or musician's intuition, and comparing distributions by Kullback-Leibler divergence or -norms (e.g., Local Key Estimation from an Audio Signal Relying on Harmonic and Metrical Structures)
# A note on complexity and duality/negative harmony
It is possible for the negative variant of a chord to have the exact same set of intervals in the same order, take for example, in 12edo, C E G B (Cmaj7), whose negative is C Ab F Db (which then is Dbmaj7). If we ignore the absolute frequency and things like the lower interval limit, then these two chords are indistinguishable up to transposition by a major 7th (or minor 2nd). Also in JI, the negative of 8:10:12:15 is itself (up to transposition). In this case, it would make sense for any complexity algorithm that is invariant over transpositions to assign the same complexity score to both chords.
However, for non-mirror symmetric chords, this property does not hold, e.g. the negative of 4:5:6:7 is 60:70:84:105, which I think should deserve a much higher complexity score. To demonstrate what I mean by "complexity", consider:
Even though all 6 pairwise dyads are the same intervals, there are other psychoacoustic features like timbral fusion/combination tones/virtual fundamental that are much weaker in the latter than in the former, which contributes to the second "negative" chord being more complex.
Put another way, if all four notes were played together (in the context of a song with other instruments playing),
...a chord would be more complex if, for an ear-trained musician/transcriber, it would be:
Harder to find all 4 notes in
4:5:6:7than in60:70:84:105, i.e., some inner voice may be missed out when attempting to transcribe. (Play the following examples with other songs playing in the background to simulate the experiment).Easier to correctly identify any of the 4 notes in
4:5:6:7than in60:70:84:105;
(Not a conclusive demo, just some anecdotal examples that may or may not work for you.)
To me, these two properties signify that 4:5:6:7 should be considered "simpler" than 60:70:84:105. This intuition guides what I want this complexity score to output.
# Algorithm v1
I will describe my algorithm using the narrative steps that I took to arrive at the final version. Though long-winded, I hope that showing what did not work can be as useful as showing what did.
The first version of the algorithm described is implemented in polyadic-v1.rs and uses dyad_lookup-old.rs for dyadic complexity/tonicity lookups.
# Goal 1: Crossing the dyadic-polyadic and micro-macro scale gap
I noticed that complexity scoring metrics either zoom in to the microscopic perspective of the complexity of each dyad and interactions between their partials (e.g., Sethares' dissmeasure, height functions) or zoom out to the macroscopic perspective to compute the score of the entire chord as a whole (e.g., HE or machine learning models).
It didn't make sense to have two fundamentally different models to describe the perception of one thing, and I want to explore the idea of the polyadic complexity/tonicity perception being an emergent property of the microscopic interactions between each pair of notes.
How can we evaluate the perception of the whole chord by only evaluating dyads (2-note chords) each time?
# Goal 2: No AI/ML (besides regressing simple statistical models)
There are models out there large enough to make sense of music. However, the two main problems I have with resorting to ML (machine learning) models are:
No explainability. There are models that are a working black-box that spits out sensible harmony, but the point of this exercise/experiment is to find whether there are any principles that influence complexity and root perception that can be made objective enough for a computer to evaluate. Of course, not everything can be explained through computation alone, but I am interested to find out the exact extent of what can and cannot be done. Hence, ML won't work for this purpose.
Not enough training data. The goal of this algorithm is to be able to analyze the complexity and tonicities of any arbitrary tunings. The inputs to the algorithm are raw Hz values, and the point is for any arbitrary frequencies from whatever tuning to be supported. The issue with most models that train on MIDI/FFT melspectrograms is the 12-centric quantization of pitch, which makes it impossible to generalize to arbitrary tunings in a way that is true to the "hidden underlying human model" of pitch and complexity perception. Ideally, the algorithm should see 12edo as a special case of the underlying logic, and any other tuning system should have exactly the same underlying logic applied.
# Base case: Dyadic complexity
Suppose we only have two notes. There are already many existing methods that give a satisfactory complexity score for dyads. I will fall back to some variant of Sethares' dissmeasure that considers the first 31 harmonics. Depending on the specific part of the algorithm, I use a version that is better suited for compounding additively or multiplicatively, or normalized (with polynomial regression) so that all octaves (besides unison) have the same dyadic complexity score. All variants look more or less the same:
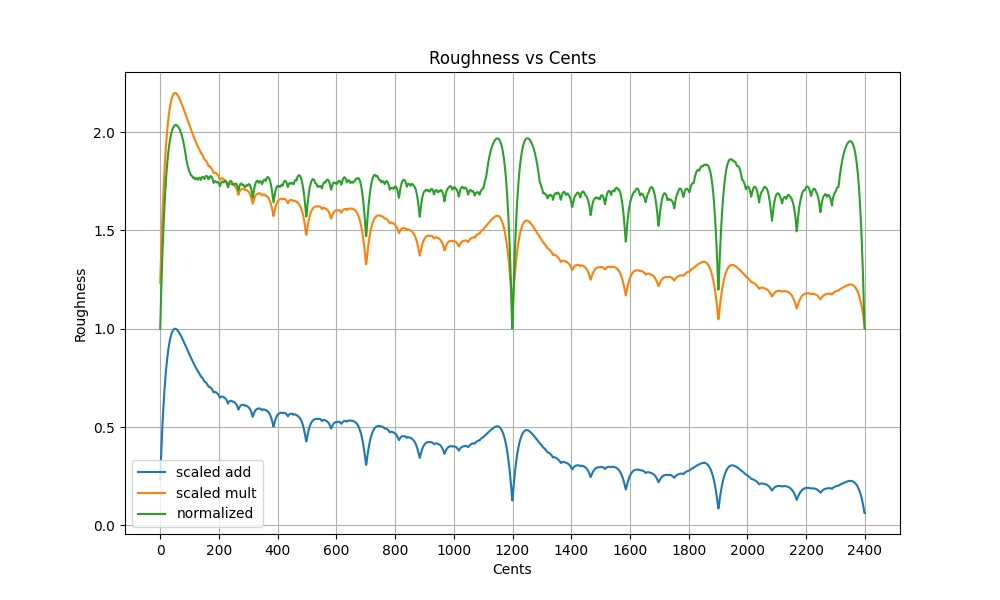
For the code that generated this plot, see the implementation of DyadLookup in dyad_lookup.rs. The same results are stored in sethares_roughness_31_5_0.95.csv.
# Base case: Dyadic tonicity
The initial tonicity heuristic can be thought of as an attempt to answer this question: Assume nothing has been played yet (no harmonic context) and the listener has no prior expectations. If both notes are played simultaneously for long enough for the listener to initially form an opinion, but short enough so that the initial opinion is not changed, which note will the listener hear as the root/tonic?
For root perception, otonality first comes to mind. First a vague definition: we consider an interval to be otonal (as in overtones) if the top note can be seen as part of the harmonic series built from the bottom note. For various possible reasons, the top note in an otonal dyad is, more often than average, perceived relative to the bottom note. In a context-free vacuum, the bottom note of an otonal dyad is more "rooted", the same way a dyad is utonal (as in undertones) if the top note is more "rooted". (E.g., sing Do-Mi, and sing Mi-Do (or Le-Do) in a different key. Repeat a few times in random keys. Which note feels more like the root?)
E.g., in a perfect fifth, C-G, we think of C as the root and G as the fifth. If we invert the interval across the octave so that G is now below C, then the perfect fourth G-C is utonal, and we still may think of C as the root and G as a fourth below the root (or historically, the C is a dissonant suspension that should resolve to B and/or D, then G is the root).
Notice the issue of duality when it comes to root detection, a V-I progression in C major can also be a I-IV progression in G major. This can be solved by applying a cultural model (e.g., require two unique clausulae, use scale/mode/melody, etc...), but for this algorithm, as long as it answered within fifth of the "culturally correct" answer, I would consider it a success.
Now I say that the above definition of otonality is vague because I notice that otonality can be defined at multiple levels, sorted in decreasing strictness:
- Strictly part of the harmonic series: only dyads are otonal for , i.e.,
3/1is otonal but3/2is not. - Part of the harmonic series up to octave displacements while preserving the direction of the interval: any dyad is otonal as long as . E.g.,
27/16is otonal but5/3is not.5/4is otonal but4/5is not (direction flipped). - Any dyad whose higher note is higher up the harmonic series than the lower note, up to octave displacement, is otonal: any for any where and is otonal, and are such that are not even. E.g.,
7/5is otonal but10/7is not. - Any dyad which is close enough to any interval that is otonal/utonal by the above definition is otonal/utonal respectively. E.g., we can consider
14/11, and also 400 cents, otonal because it is close to5/4and81/64. The closer the interval is to other simple JI otonal/utonal intervals, and the simpler (lower height) of those JI intervals, the stronger the pull towards that classification.
These levels of definitions create a continuum of otonality/utonality. @hyperbolekillsme on the Xenharmonic Alliance Discord generated a plot using this python script which evaluates the otonality of intervals (otonality in blue line):
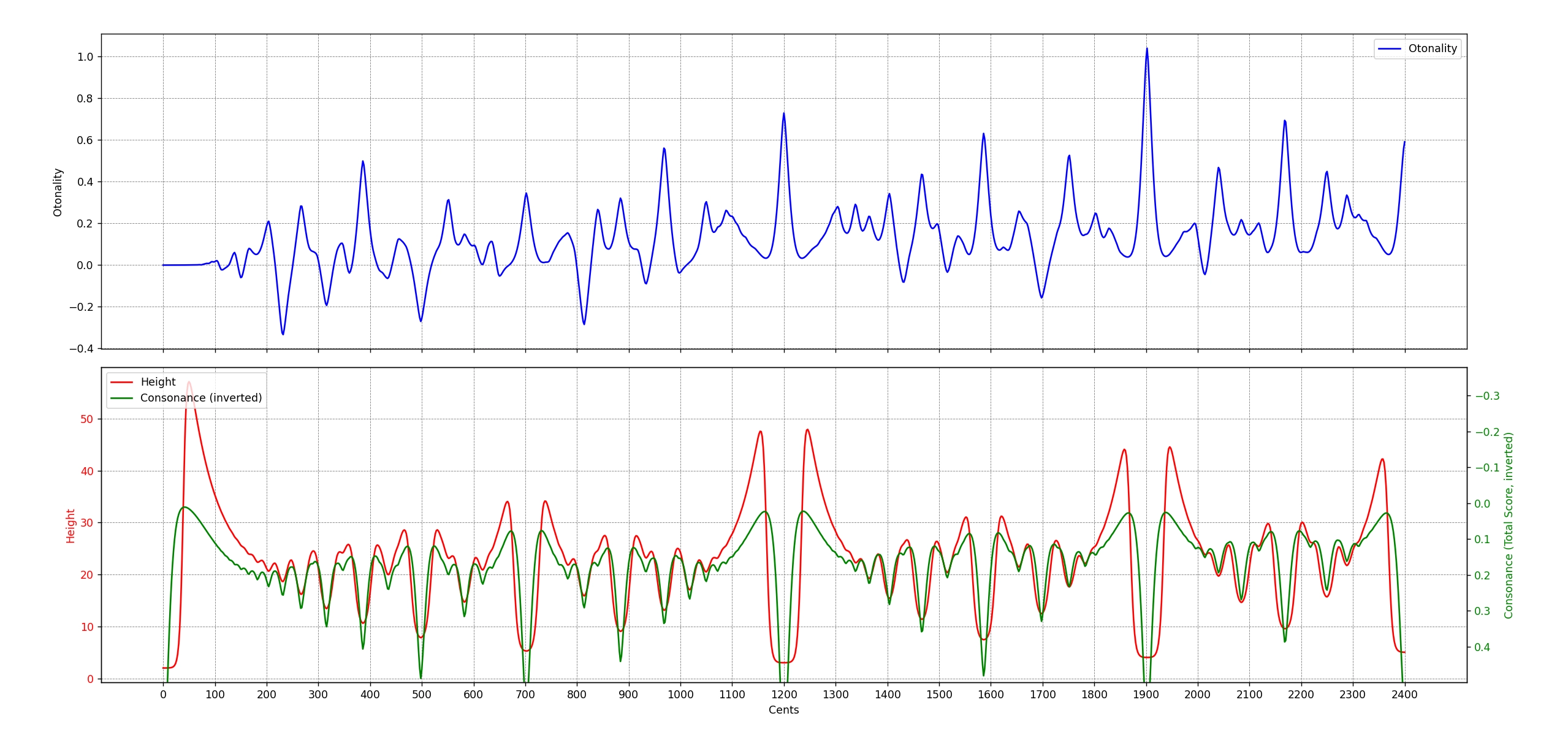
This was done by computing the otonality component for the numerator and denominator of each JI up to a fixed height using multiplicative Euler complexity (as @hyperbolekillsme calls it): e.g., , where and are primes. Then, raw otonality for a JI interval is computed as
For any interval (not necessarily JI), its otonality is computed by finding a set of JI approximations via find_top_approximations, then those approximations are scored/weighted by score = complexity_score * accuracy_score. The otonality is the weighted average otonality(a, b) * score.
This otonality scoring metric is consistent with definition 4. of otonality above.
One easy method to apply otonality to obtain an initial heuristic of tonicity is to sum up, for each pair of notes in a chord, how otonal each pair is. The more otonal a pair is, the more we increase the tonicity score of the lower note in the pair.
However, there are two things that prevented me from taking this approach:
The otonality curve itself didn't agree with my intuition for rootedness. For instance, I would think that in a vacuum, a
3/2perfect fifth C-G, or even more so, a stack of perfect fifths C-G-D-A, would imply more tonicity for C than a single5/4major third. This does not work with the otonality curve which ranks5/4and7/4much more otonal than3/2.I don't think that otonality can substitute for tonicity/root perception — e.g., the minor tonality is built of the minor third, but 6:5 is a utonal interval (unless we are considering the minor third 7:6 or 19:16)
Rather than otonality, I thought about what other properties I could exploit to highlight the asymmetry between "root" and "non-root" notes. Specifically, I was drawn to the asymmetry of the roughness curve itself.
To show what I mean by "asymmetry", let's suppose that:
- The duals of negative harmony are equivalent.
- Octaves are equivalent.
Then, P5 = 3/2 and its dual -P5 = P4 - 1 octave = 2/3 must be equivalent. And because of octave equivalence, 2/3 should be equal to P4 = 4/3.
However, the roughness of 3/2 and 4/3 are not equal. This is the asymmetry that I want to exploit.
From the bias of my musical cultural entrainment, 3/2 reinforces the lower note as root and 4/3 reinforces the higher note as root. Since 3/2 has lower roughness than 4/3, I hypothesize that if an (octave-shifted) inverted interval has higher roughness than the original interval, then the original interval reinforces the lower note as root more strongly than the higher note, and vice versa.
Intuitively: If an interval has lower roughness than its octave-inverted counterpart, then the lower note of the original interval "wants" to be the lower note. Conversely, the inverted configuration having a higher roughness than the original interval could indicate that the inverted configuration is less stable.
Using this idea, I generated a plot for the initial heuristic tonicity score of a dyad in vacuum:
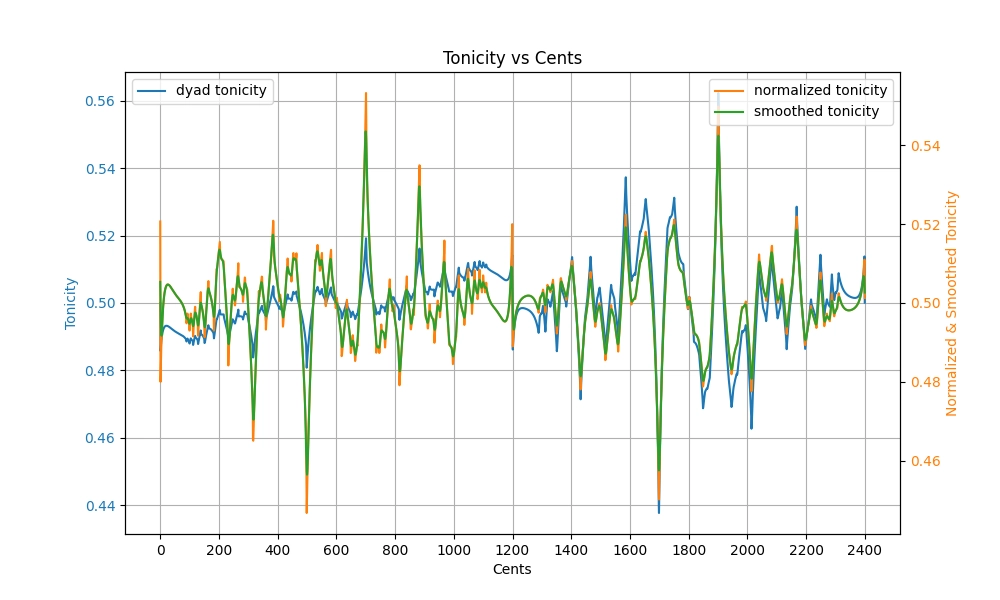
The code that generated this plot can be found in the implementation of TonicityLookup in dyad_lookup.rs, and the results are stored in dyad_tonicity_19_5_0.95.csv.
The higher the tonicity, the more likely the lower note is to be heard as root/tonic.
The blue line is the raw dyad tonicity, computed as
whererough is the normalized dyadic roughness (the green line in Base case: Dyadic complexity), is the interval in cents, and is its inverted counterpart, placed within the same octave as .The orange line is the normalized tonicity. Because Sethares' roughness intrinsically decreases as two intervals get further and further apart, there is a drifting bias such that larger intervals always have lower roughness and thus higher tonicity than smaller intervals. To correct for this, each octave is fitted to a degree 5 polynomial and that is subtracted from the raw tonicity to obtain a flatter version, then the result is normalized with mean 0.5 and variance 0.0001. The choice of variance here is arbitrary, but I just needed to make the tonicity scores fit within 0.4-0.6 for numerical stability in the later time/context-sensitive parts of this algorithm.
Finally, the green line (smoothed tonicity) is obtained by applying Gaussian kernel smoothing with 21 bins ( cents) at cents, since humans don't perceive pitch with infinite precision, a lot of the sub-cent jitters are not very meaningful. This smoothed tonicity is used in the rest of the algorithm and referred to as dyadic tonicity.
Generally, I am quite satisfied with the smoothed tonicity (green), except for the fact that 5/3 scores higher tonicity than 5/4 (to my cultural bias, 5/3 in a vacuum should imply a third note 4/3 as tonic instead). At this point in time, I didn't think it would be an issue, so I just moved on.
# First step: Major vs minor triads
Now that I had a way of initially guessing which note is more likely the root in a dyad, I can move on to triads.
The main challenge of dyadic methods is to ensure that the 5-limit JI major triad 4:5:6; and the minor triad 10:12:15 do not have the same complexity score. The minor triad should be more complex.
My thought process:
- In a vacuum, when I hear both
4:5:6and10:12:15, I would instinctively hear the lowest note as the root, the top note as a fifth coloring above the root, and the middle note as the note that helps identify the quality of a chord. - I would judge the notes in the triad relative to the most rooted note, followed by the fifth, then lastly the middle note. E.g., if I hear C-E-G in a vacuum, I wouldn't instinctively think of judging C as the b6 of E unless forced to by some other context.
- Therefore, there must be a way to ascertain how "tonic" each note in the triad is, then use that to weight the importance of each dyad's complexity score.
First, suppose we don't weight by tonicity, and let be the complexity scores of the dyads C-G, C-E, and E-G respectively, where .
Also (assuming complexity is invariant to transposition), will be the complexity of C-G, Eb-G, and C-Eb in the minor triad.
If we only sum up the dyadic complexities, both C-E-G and C-Eb-G will have the same total complexity of .
However, now suppose we have tonicity scores for each note. Let be tonicity scores for the major triad and let be tonicity scores for the minor triad.
If we have a function that takes in dyadic complexity and tonicity scores of notes and and spits out a weighted complexity score, then the total complexity score for the major triad can be
and that of the minor triad is Thus, if and , then the complexity of the major triad can be different from that of the minor triad.Some choices of :
Let's work out some numbers to see if this works.
For exaple, we can try this simple heuristic to get the tonicity of the notes in the triad:
- For each dyad, add the
dyadic_tonicityto the lower note's raw tonicity score, and add1 - dyadic_tonicityto the higher note's raw tonicity score. - Take the average tonicity score for each note by dividing by the number of dyads it is part of (i.e., divide by where is the number of notes in the chord).
- Apply softmax on average tonicity scores to get a probability distribution summing to 1.
According to the comutations in Base case: Dyadic complexity and Base case: Dyadic tonicity, we have:
| Dyad | Dyadic complexity | Dyadic tonicity |
|---|---|---|
| C-Eb and E-G | 1.764 | 0.4983 |
| C-E and Eb-G | 1.759 | 0.5043 |
| C-G | 1.512 | 0.55 |
Raw tonicity scores (Major):
- C:
- E:
- G:
Raw tonicity scores (Minor):
- C:
- Eb:
- G:
Softmax tonicity scores (Major):
- C:
- E: 0.3323
- G: 0.3253
Softmax tonicity scores (Minor):
- C: 0.3414
- Eb: 0.3343
- G: 0.3243
Using , we have:
Or using :
Note that the minor triad is only very slightly more complex than the major triad. The major-minor complexity gap can be widened further by decreasing the softmax temperature to give more opinionated tonicity scores, or by tweaking .
This is just an initial heuristic tonicity score, but I will later use a contextual model of tonicity that becomes more opinionated over time, so the small difference between tonicities is not of concern for now.
# Generalizing: Polyadic complexity using interpretation trees
We can trivially extend to 7-note chords from the triad case by repeating the same sum-of-tonicities and softmax normalization to get tonicities of each note in the chord, then summing up the weighted dyadic complexities for each pair of notes.
However, in my experiments, this completely misses the gestalt of the chord. E.g., a common voicing for a C13b9 chord is C Bb for the left hand and E A Db in the right hand. Now, the E A C#/Db forms an A major triad upper structure that easily stands out in the chord (because of its consonance). At the same time, I recognize C Bb E as a dominant 7th fragment.
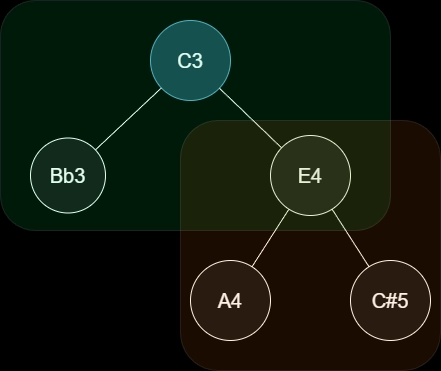
The interpretation tree above implies that we hear A and C# with respect to E as a "subroot", and we hear Bb and E with respect to C as the root. Of course, this is not the only way to interpret this voicing, so the algorithm should also aggregate over different interpretations later.
To evaluate complexity based on this particular interpretation tree:
- Compute the initial tonicities of the notes in this set-up, we use the heuristic initial tonicity computation in the first step. Though in practice, notes are only added one at a time, so we can assume that the contextual tonicities is already given except when adding new notes.
- Perform a DFS (depth-first search) starting from the root node (C3):
- Compute the local relative tonicity amongst all children. I.e., assuming the current tonicity scores of the entire chord from context, we take the distribution conditioning on the parent node being the root. See below for various methods for obtaining local tonicity scores.
- For each child of the parent:
Compute the complexity of child subtree recursively. If the child is a leaf node, it has complexity 0. This value should be contained in .
Obtain the edge complexity in , which is obtained from a lookup table from the pre-computed dyadic complexities between the parent and the child. This complexity should model perceived roughness, thus the same interval at different octaves should generally have lower complexity the further apart they are. However, the raw additive Sethares' roughness is normalized to have a peak roughness that halves every octave. Instead, I want to aim for peak roughness to be at the -th octave, so we simply multiply the raw additive roughness by for octaves.
The child's complexity (in the range 0-1) is computed as:
where is the dyadic complexity between parent and child and is the subtree complexity of the child subtree.
This formula was chosen so that:
- : neutral complexity of both edge and subtree should return neutral 0.5.
- : average complexity 0.5 should be preserved in recursive steps.
- If , : edge complexity should have more effect than subtree complexity on overall complexity. This ensures more intuitive root choices will score lower complexity. If this inequality was flipped, optimizing for low-complexity roots will optimize for interpretation trees where the root is the largest "dissonance contributor" — in the sense that if the root is removed, the remaining notes (which are siblings/descendants of the children) will be the most consonant.
- and : bounding min/max cases should give min/max values
- is bounded with the same bounds as inputs.
Question
Is there a better way to combine edge complexity and subtree complexity, in a way that is explainable by human perception, rather than just using intuitive mathematical properties?
This is not the final edge complexity vs. subtree complexity balancing method, a modification will be made later.
- Then, the total complexity of the parent's subtree is computed as the weighted sum of all its children's complexities, weighted by local tonicity of each child.
- The final complexity, fixing this interpretation tree of the voicing, is obtained when the root node (C3) is reached.
I have considered different options for evaluating the local tonicity distribution, conditioning on the parent note as root:
Normalize tonicity scores of child nodes to 1. This is computationally efficient, but the issue would be that if a child node has very low tonicity, the complexity of the child's subtree (if any) will be discounted.
- Problem: If we optimize root choice and tree structure for low complexities at the subtree level there would be a feedback loop where low-tonicity subtree roots are preferred, which doesn't make sense since the main point of the model is for parents to have higher tonicity than their children.
- Solution 1: decouple tonicity calculation from subtree complexity computation, then this issue is avoided.
- E.g., we can compute the target tonicity by comparing the distributions of complexity scores obtained by fixing each note as root. E.g., increase the tonicity of a note if the minimum complexity score when that note is root is lower than the rest, and scale the increase by the confidence (e.g., we can measure confidence as the entropy of complexity score distributions fixing each note as root, or as the inverse of the variance of complexity scores)
- Solution 2: Intuitively, any node with low (global & local) tonicity should not have many children, as the point of tonicity is to model how likely a note is to be heard as the baseline reference for other notes. To regularize this, we can penalize configurations where low-tonicity parents have many children which evades the complexity contributed by edges formed between the parent and their children. Alternatively, we can penalize when children have higher tonicity than their parents.
- Solution 1: decouple tonicity calculation from subtree complexity computation, then this issue is avoided.
- Problem: If we optimize root choice and tree structure for low complexities at the subtree level there would be a feedback loop where low-tonicity subtree roots are preferred, which doesn't make sense since the main point of the model is for parents to have higher tonicity than their children.
Instead of computing local tonicity scores using only tonicities of direct children, the relative tonicity of each child will be the sum of tonicities of the child itself and all its descendants (or some kind of aggregation function that increases if the tonicity of all elements in the subtree increases, e.g. softmax of values where is the sum of tonicities for the -th child's subtree).
- This will be the method I am currently developing for this article. This method comes with its fair share of problems which we will go through later.
Compute local tonicity of each child using the reciprocal of the child's subtree complexity. The intuition here is that if a subtree is a concordant/stable upper structure, it is more likely to be heard as a reference point over other substructures.
- Problem 1: If the child is a leaf node, there is no complexity scoring for just a single note. When comparing the tonicities of child leaf nodes to each other, we can use the global tonicity context and normalize their per-note global tonicities to get a local tonicity distribution. However, how do we compare a leaf node to a non-leaf node, such as in the C13b9 example where Bb is a child leaf node of C but E-A-C# is a child subtree of C?
- Solution: mix both local tonicity from global context and reciprocal subtree complexity. For a non-leaf note node , let be its global tonicity and be the subtree complexity, then we can define the mixed tonicity as where is a parameter controlling how much bonus we give to low-complexity subtrees, and is the expected subtree complexity score of all subtrees with the same number of notes of the subtree at .
- This solution introduces more parameters and the computation of for each subtree size is memoizable but not trivial, so I have not experimented with subtracting yet.
- Problem 2: The subtree complexity is computed as the sum of child subtree complexities weighted by the child subtree's tonicity. However, now the child subtree's tonicity is simply the reciprocal of its complexity, so now multiplying the local tonicity and complexity simply cancels out to a constant!
- Solution: from the distribution created from the mixed tonicities as a solution to Problem 1 above, we combine the reciprocal subtree complexity with an edge-specific weight in a non-linear way (e.g., multiplying the dyadic complexity and the reciprocal subtree complexity).
- Problem 1: If the child is a leaf node, there is no complexity scoring for just a single note. When comparing the tonicities of child leaf nodes to each other, we can use the global tonicity context and normalize their per-note global tonicities to get a local tonicity distribution. However, how do we compare a leaf node to a non-leaf node, such as in the C13b9 example where Bb is a child leaf node of C but E-A-C# is a child subtree of C?
Note
In my initial attempt (polyadic-old.rs), I have gone with method 3, however, this raised the computational complexity so high that the algorithm can no longer run at real time unless aggressive beam pruning was done, but that severely impacted accuracy.
In this article, I aim to use method 2, but the computational complexity is still relatively high, so some optimizations were done to prune the search space of possible trees.
This completes the first part — now we can evaluate the complexity given a single subjective interpretation of how a polyadic chord voicing is broken down.
# Generalizing: Polyadic tonicity evolving with time
The next challenge: How to aggregate over different interpretations of the same voicing to form a single complexity score?
Going back to the C13b9 voicing example, note that there are many other ways of interpreting this particular voicing, and not necessarily with C as the root. Though, certain ways of interpreting will feel more intuitive than others. How do we model this?
- E.g., we could also interpret the voicing as an Bbdim (Bb Db E) over an Am dyad (A C), but this does not feel intuitive to me.
In hindsight
At this current stage, I assumed that explicitly scoring the likelihoods of the tree interpretation was not necessary since the complexity scores aggregated from each root of the interpretation tree are fed back in to the algorithm to update the tonicity scores, which I assumed meant that tonicities should converge to a value that depends on the likelihoods of the trees with that root.
In the next step, I will show why this is not sufficient.
- E.g., we could also interpret the voicing as an Bbdim (Bb Db E) over an Am dyad (A C), but this does not feel intuitive to me.
How do we update the perceived tonicity of notes according to the aggregated polyadic complexity calculations (instead of relying on the heuristic polyadic tonicity in First step: Major vs minor triads)?

To give another example, compare this voicing of 13b9 to other voicings with octaves shifted around:
I think it's fair to say all these voicings of C13b9 have differing perceived complexities, and there is a reason why some are more commonly played than others.
When there are more notes, certain subsets or upper structures stand out as strong units on their own, and usually depends on the exact voicing being played. This may very well just be a cultural artifact of how contemporary western harmony is organized, but I wanted something in the model that can capture this idea.
This is what a full single-tick update of the algorithm should look like, assuming no new notes were played, no old notes were deleted from the context, and the tonicity values of all notes in the chord are known and correct:
Iterate over different interpretations of the same voicing (finding different substructures)
Identify which choices of tree organization and root choices are more likely than others
- The likeliness of root choices are used to update the global tonicity values.
Aggregate substructures into individual units, where each substructure has a "structure tonicity" and "structure complexity" score, weighted amongst other sibling leaf nodes/substructures at that level.
Step 3 is already handled by the single-interpretation case.
For step 2, we have to devise a measure of likelihood. For now, we focus on the simpler problem of measuring the likelihood of root choices, which directly corresponds to the tonicity scores. (In the next section, we find that we still have to model the intuitiveness/probability of perceiving each tree, see The big problem: Duality is still hiding)
Working through an example for triads, we have to think about 3 tree configurations and 3 different roots each:
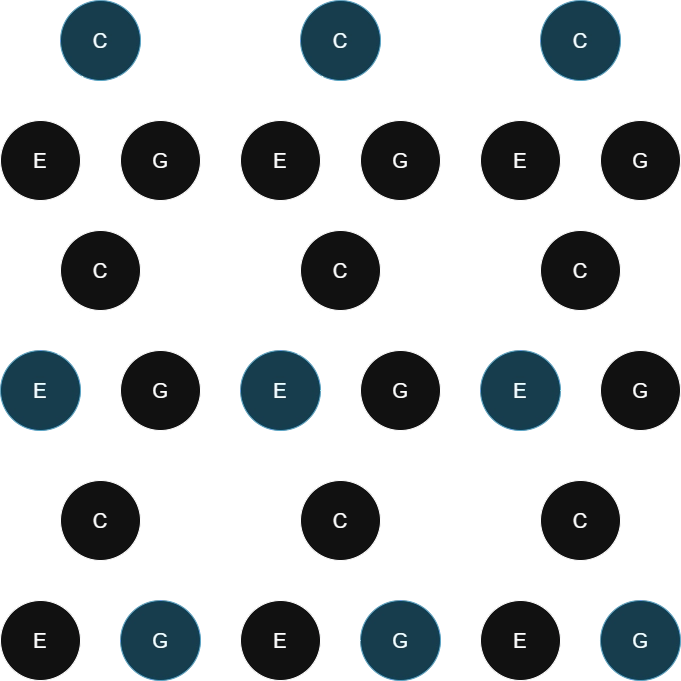
Using the interpretation tree complexity evaluation from Generalizing: Polyadic tonicity with substructures, we can compute the complexity score for each of the 9 configurations above. An example of how this can be done using depth-first search (DFS) in the triadic case is provided in triad_sts_computation_example.py. Running test_one_iteration() gives the result:
Code
C
|---E
|---G
Complexity: 0.63550
___________________________
C
|---E
|---G
Complexity: 0.75960
___________________________
C
|---G
|---E
Complexity: 0.55761
___________________________
Arithmetic mean complexity for root C: 0.65090
Harmonic mean complexity for root C: 0.64056
Inverse exp. weighted mean complexity for root C: 0.64407
Exp. weighted mean complexity for root C: 0.65789
E
|---C
|---G
Complexity: 0.76150
___________________________
E
|---C
|---G
Complexity: 0.71398
___________________________
E
|---G
|---C
Complexity: 0.71839
___________________________
Arithmetic mean complexity for root E: 0.73129
Harmonic mean complexity for root E: 0.73067
Inverse exp. weighted mean complexity for root E: 0.73083
Exp. weighted mean complexity for root E: 0.73175
G
|---C
|---E
Complexity: 0.63800
___________________________
G
|---C
|---E
Complexity: 0.55702
___________________________
G
|---E
|---C
Complexity: 0.76340
___________________________
Arithmetic mean complexity for root G: 0.65281
Harmonic mean complexity for root G: 0.64204
Inverse exp. weighted mean complexity for root G: 0.64569
Exp. weighted mean complexity for root G: 0.66008
Now this test assumes an initial uniform tonicity, where all C, E, and G have the same tonicity probability of .
Even then, we notice that the average complexity scores per choice of root are not equal. The lowest average complexity is obtained when C is the root, followed by G, then E, which I find is an acceptable answer to the question: "With no prior musical context, if you hear a simple C-E-G triad in root position as the first stimulus of a song, and given that the key of the song is either C, E, or G major or minor, which key do you think the song will be in?". I find the slight ambiguity between C and G acceptable because of the duality problem mentioned in Base case: Dyadic tonicity.
The results of this test hints that the per-root aggregated polyadic complexity scores can be used directly to nudge the tonicity context towards favouring roots with lower complexity scores.
Four different aggregation methods were tested: Where is the complexity score for the -th interpretation tree of the same root,
- Arithmetic mean:
- Complexities are weighted equally.
- Harmonic mean:
- Complexities with smaller values are weighted more heavily.
- Inverse exponential weighted mean:
- Complexities with smaller values are weighted more heavily, but less aggressively than harmonic mean.
- Exponential weighted mean:
- Complexities with smaller values are weighted less heavily.
Initially, I was inclined to use either the harmonic or inverse exp weighted mean, because intuitively I thought that if a particular root interpretation allows for a few interpretation trees to have significantly lower complexity than the rest, then the listener should update their subjective model of tonicity to favor hearing the current music with respect to whichever root that allows for an interpretation that obtains the least complexity.
However, in terms of raw numbers, I wanted to widen the gap between the probability of C being the root and the probability of G being the root. Hence, I at this point I considered using the exponentially weighted mean to aggregate per-root complexities. Musically speaking, this means that if any root choice allows for the listener to construct a high-complexity interpretation, that high-complexity interpretation would affect the overall complexity score of that root choice more significantly than a low-complexity interpretation would, e.g., multiple low-complexity interpretations are needed to "balance out" a single high-complexity interpretation.
In hindsight
This aggregation method is flawed — this will be improved in the next sections.
Now that the per-root aggregated complexities are computed, we can update the global tonicity scores as follows:
Compute target tonicities as the softmax of negative per-root complexities (adding 1 for numerical stability). Where is the target tonicity of the -th note, is the aggregated complexity scores of interpretation trees with note as the root, and is the softmax temperature (which is lowered from the baseline of 1 to make the tonicity distribution more opinionated):
Perform smooth update of global tonicity context towards the target tonicities. is the current global tonicity of note , and is the smoothing factor (higher = slower update), we compute the next iteration's global tonicity using
then we normalize with such that is a tonicity distribution.
The updated tonicity scores are now fed back to the complexity computation for the next tick.
This process continues indefinitely until the music stops.
An example of this computation is provided in triad_sts_computation_example.py in the function test_tonicity_update(). Running it to update the tonicities of a simple C-E-G triad with parameters iterations=30, smoothing=0.7, temperature=0.5 and assuming an initial uniform tonicity of gives the result:
Code
Iteration 1 target: ['0.34986', '0.30181', '0.34833'] ctx: ['0.33829', '0.32388', '0.33783']
Iteration 2 target: ['0.34994', '0.30163', '0.34843'] ctx: ['0.34179', '0.31720', '0.34101']
Iteration 3 target: ['0.35000', '0.30150', '0.34850'] ctx: ['0.34425', '0.31249', '0.34326']
Iteration 4 target: ['0.35004', '0.30141', '0.34854'] ctx: ['0.34599', '0.30917', '0.34484']
Iteration 5 target: ['0.35007', '0.30135', '0.34858'] ctx: ['0.34721', '0.30682', '0.34596']
Iteration 6 target: ['0.35009', '0.30130', '0.34860'] ctx: ['0.34808', '0.30517', '0.34676']
Iteration 7 target: ['0.35011', '0.30127', '0.34862'] ctx: ['0.34869', '0.30400', '0.34732']
Iteration 8 target: ['0.35012', '0.30125', '0.34863'] ctx: ['0.34912', '0.30317', '0.34771']
Iteration 9 target: ['0.35013', '0.30123', '0.34864'] ctx: ['0.34942', '0.30259', '0.34799']
Iteration 10 target: ['0.35013', '0.30122', '0.34865'] ctx: ['0.34963', '0.30218', '0.34819']
Iteration 11 target: ['0.35014', '0.30121', '0.34865'] ctx: ['0.34979', '0.30189', '0.34833']
Iteration 12 target: ['0.35014', '0.30120', '0.34866'] ctx: ['0.34989', '0.30168', '0.34843']
Iteration 13 target: ['0.35014', '0.30120', '0.34866'] ctx: ['0.34997', '0.30154', '0.34850']
Iteration 14 target: ['0.35014', '0.30120', '0.34866'] ctx: ['0.35002', '0.30144', '0.34854']
Iteration 15 target: ['0.35014', '0.30120', '0.34866'] ctx: ['0.35006', '0.30136', '0.34858']
Iteration 16 target: ['0.35014', '0.30119', '0.34866'] ctx: ['0.35008', '0.30131', '0.34860']
Iteration 17 target: ['0.35014', '0.30119', '0.34866'] ctx: ['0.35010', '0.30128', '0.34862']
Iteration 18 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35011', '0.30125', '0.34863']
Iteration 19 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35012', '0.30123', '0.34864']
Iteration 20 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35013', '0.30122', '0.34865']
Iteration 21 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35013', '0.30121', '0.34865']
Iteration 22 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35014', '0.30121', '0.34866']
Iteration 23 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35014', '0.30120', '0.34866']
Iteration 24 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35014', '0.30120', '0.34866']
Iteration 25 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35014', '0.30120', '0.34866']
Iteration 26 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35014', '0.30119', '0.34866']
Iteration 27 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35014', '0.30119', '0.34866']
Iteration 28 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35014', '0.30119', '0.34866']
Iteration 29 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35015', '0.30119', '0.34866']
Iteration 30 target: ['0.35015', '0.30119', '0.34866'] ctx: ['0.35015', '0.30119', '0.34866']
And we can see that the tonicity scores being fed back to the complexity algorithm converges to tonicities:
- C: 0.35015
- E: 0.30119
- G: 0.34866
The variance/opinionatedness/confidence of tonicity scores can be increased by decreasing the temperature parameter further, and the rate of convergence can be adjusted by changing the smoothing parameter. Ideally, we want to run this at 60 fps — in practice, the smoothing parameter is scaled by delta time of each frame to ensure a constant rate of update.
# "Final" tonicity calculation
Now it is possible to evaluate the complexity of each interpretation tree, and update tonicities of each note based on the per-root aggregated complexity scores. The final dissonance score of the entire voicing is computed as:
where is the aggregated complexity score (as per the above section) of all interpretation trees rooted at note , and is the tonicity of note from the existing tonicity context.
After the harmonic analysis algorithm is finalized, the plan is to add rhythmic beat entrainment and harmonic rhythm entrainment to the model, such that the tonicity model becomes more sensitive (lower smoothing and lower temperature) when it is near a strong downbeat or an expected harmonic/chord change based on the rhythmic entrainment model.
# Algorithm v2
# The big problem: Duality is still hiding
It seems like the above methodology is complete and achieves the initial goals of non-duality, polyadic gestalt, and building a model of complexity and root perception as an emergent property of dyadic relationships in a tree structure.
However, after fully implementing the above algorithm in Rust, certain tests reveal huge red flags. In the following tests, I have initialized the tonicity context using the dyadic-sum-softmax heuristic from First step: Major vs minor triads, then ran one iteration of the tree-based update algorithm (at 1s delta time). Each chord voicing is evaluated in a vacuum with the context reset to the initial heuristic value.
Note
To interpret the output:
Voicingare cents values of notes. The order of the notes in this voicing determines the order of the tonicity values. 0 cents = A4 = 440hz as an arbitrary reference point (lower interval limit is accounted for), but for simplicity in the section below, I will refer to 0 cents as C instead of A.Dissis the final dissonance score calculated as where is the aggregated complexity score of all interpretation trees rooted at note , and is the tonicity of note from the existing tonicity context, which is the tonicities computed from the dyadic tonicity heuristic model.tonicity_targetis the target tonicities computed from the aggregated complexity scores per root.tonicity_contextis the current active tonicity context, which converges towards the target tonicities over time.The numbering of interpretation tree nodes in
Lowest 3 complexity treescorrespond to notes of the voicing in ascending pitch order, not necessarily the same order as listed inVoicing.
Code
============ Graph diss: P4 =====================
Voicing:
0.00c
500.00c
Diss: 0.4430
2.5s: [
Dissonance {
dissonance: 0.44301372910812864,
tonicity_target: [
0.5,
0.5,
],
tonicity_context: [
0.49898347292521467,
0.5010165270747854,
],
},
]
Lowest 3 complexity trees for root 0.00c:
-> comp 0.4430:
0
└── 1
Lowest 3 complexity trees for root 500.00c:
-> comp 0.4430:
1
└── 0
============ Graph diss: P5 =====================
Voicing:
0.00c
700.00c
Diss: 0.3195
2.5s: [
Dissonance {
dissonance: 0.31948576531662115,
tonicity_target: [
0.5,
0.5,
],
tonicity_context: [
0.5010165261177496,
0.4989834738822504,
],
},
]
Lowest 3 complexity trees for root 0.00c:
-> comp 0.3195:
0
└── 1
Lowest 3 complexity trees for root 700.00c:
-> comp 0.3195:
1
└── 0
In the above dyadic scenarios of the perfect fourth and fifth, the glaring problem is that the tonicity_target is perfectly uniform, i.e., 50% chance that either the lower or higher note is the root.
This was not what the initial heuristic model predicted (we can see the smoothed tonicity_context), and this does not agree with my intuition that I wanted to model in this algorithm.
It's easy to see why: in this case, there are only two possible interpretation trees, one for each root. Both trees have the same complexity score since it is one parent and one child (so the local tonicity of the child is always 100%), so the only factor that determines the final complexity of each interpretation tree is the edge dyadic complexity between the two notes.
This edge dyadic complexity is fully symmetric/dual, so both choices of root note always give the same complexity score (0.4430 for P4 and 0.3195 for P5).
Initially, I thought that the easy fix was to implement a special case for dyads, after all there was the dyadic tonicity model that I was already happy with in Base case: dyadic complexity.
However, the following triadic test cases revealed deeper issues:
Code
============ Graph diss: C maj =====================
Voicing:
0.00c
400.00c
700.00c
Diss: 0.4885
2.5s: [
Dissonance {
dissonance: 0.48849305288177675,
tonicity_target: [
0.34949708791695255,
0.30976802861030506,
0.3407348834727424,
],
tonicity_context: [
0.3492957038643127,
0.31039683349660957,
0.3403074626390778,
],
},
]
Lowest 3 complexity trees for root 0.00c:
-> comp 0.3954:
0
└── 2
└── 1
-> comp 0.4403:
0
├── 1
└── 2
-> comp 0.5691:
0
└── 1
└── 2
Lowest 3 complexity trees for root 400.00c:
-> comp 0.4932:
1
└── 0
└── 2
-> comp 0.5249:
1
└── 2
└── 0
-> comp 0.5804:
1
├── 0
└── 2
Lowest 3 complexity trees for root 700.00c:
-> comp 0.3870:
2
└── 0
└── 1
-> comp 0.4580:
2
├── 0
└── 1
-> comp 0.5924:
2
└── 1
└── 0
============ Graph diss: C min =====================
Voicing:
0.00c
300.00c
700.00c
Diss: 0.4890
2.5s: [
Dissonance {
dissonance: 0.4889643528743752,
tonicity_target: [
0.3401420078466398,
0.30971626450672535,
0.3501417276466349,
],
tonicity_context: [
0.34019583693360894,
0.3103994755135822,
0.34940468755280896,
],
},
]
Three glaring problems:
In the C minor triad (C-Eb-G) case, it is saying that the top note (G) should have the highest probability of being root. Clearly this does not model the average musical intuition.
- I have left out the lowest complexity trees for C minor for brevity, but G being the most probable root implies that the trees rooted at G are deemed simpler than trees rooted at C by the current model. The reason for this is found in the second problem:
Looking closely at the lowest complexity interpretation trees for C major with root C, and comparing that of root G, we see that the tree
0->2->1(interpreted as: C is root, G is P5 of C, E is m3 below G) has complexity0.3954, and the tree2->0->1(interpreted as: G is root, C is P5 below G, E is M3 above C) has a lower complexity of0.3870. Even worse still, both of these interpretation trees score with a lower complexity score than what I think would be the most intuitive interpretation:C->(E, G), i.e., C is the root, E is the M3 of the root, and G is the P5 of the root.The discrepancy between
C->G->EandG->C->Ehappens because our current algorithm only considers local tonicities between siblings, but these "trees" are simply paths/linked-lists where each parent only has one child, so there are no siblings to compare local tonicities with, resulting in tonicity scores being completely ignored in the tree's complexity calculation. The only time a note's tonicity is being used is in the final calculation of overall dissonance where the per-root aggregate complexity is weighted by the note's global tonicity.Notice how the algorithm is not modelling the fact that C->G is a much more sane interpretation than G->C for a basic 1-3-5 triad.
The single-child depth-2 paths
C->G->EandG->C->Eboth score lower in complexity than the intuitiveC->(E, G)interpretation because:- The current function that aggregates a note's subtree complexity with its dyadic edge complexity between its parent and the note itself (see step 2c of tree complexity computation) penalizes edge complexity more than subtree complexity, i.e., if , then : edge complexity should have more effect than subtree complexity on overall complexity
- There is no penalty for deep/nested interpretations, when intuitively, deeply nested interpretations (note A is seen with respect to note B seen with respect to note C, etc...) are generally more complex than flat interpretations (notes A, B, C are seen with respect to some root directly), unless there is a good reason to use a nested interpretation (e.g., the A maj triad upper structure in the C13b9 voicing discussed earlier).
The dissonance score of the major and minor triads are still nearly identical! One of the core criteria of this algorithm is to break the curse of harmonic duality in dyadic-based models, but this issue is still here.
Finally, one last test case that really makes no sense:
Code
============ Graph diss: C maj7 =====================
Voicing:
0.00c
400.00c
700.00c
1100.00c
Diss: 0.4638
2.5s: [
Dissonance {
dissonance: 0.4638236840323294,
tonicity_target: [
0.25847518240587736,
0.24130394436259714,
0.24142014916913435,
0.2588007240623913,
],
tonicity_context: [
0.2583230183357106,
0.24164858173458328,
0.2416042487186883,
0.2584241512110178,
],
},
]
This one just says that the most probable root in a Cmaj7 voiced as a plain old C-E-G-B is B. Clearly something isn't right.
# Analyzing information flow of the flawed model: Dyadic tonicity is vanishing
The solution to these issues becomes clear when we map out exactly which variables are allowed to affect which other variables. The flowchart below shows the flow of information in the above flawed model:
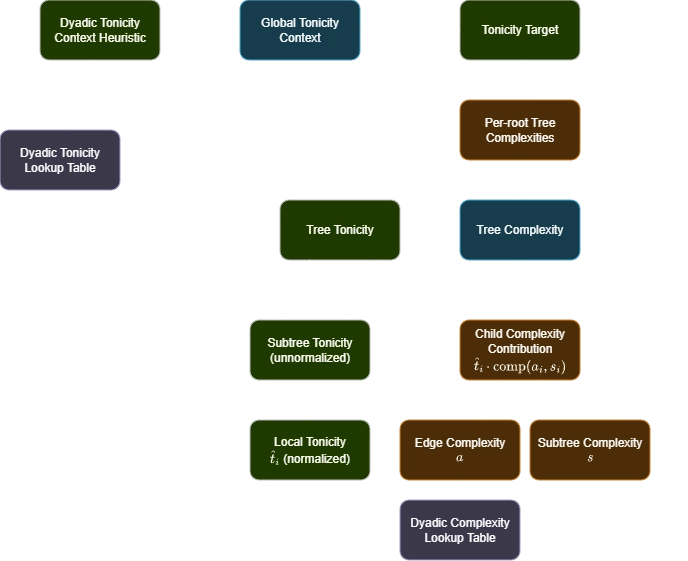
The main issue is that the dyadic tonicity is not part of the recursion, it is only used to initialize the model. Recall that the tonicity score between two notes is the only source of asymmetry/non-duality in this model — this asymmetry was the entire motivation for introducing the concept of tonicity in Base case: Dyadic tonicity.
Since dyadic tonicity is not part of the recursion and every other part of this model is symmetric (as in, harmonic duality of major/minor), over time the model will always converge to a dualistic model.
Exit plan
One possible solution is to not use a tree structure/recursion at all, and just directly combine dyadic tonicities with dyadic complexity scores.
However, I wanted the gestalt property of substructures to be modelled, so I could not do away with the tree-based interpretation.
To solve this, we have to find a way to incorporate dyadic/edge tonicities in the recursion.
My first instinct is to look at the weak spots of this model to find where dyadic tonicities can be added:
The function for combining edge and subtree complexities.
- This function was heuristically made to combine the edge and subtree complexity scores, but the arbitrary precedence of edge complexity over subtree complexity just to get better triadic tonicity results was suspicious.
The subtree tonicity score is solely computed as the sum of global tonicities of all nodes in the subtree, there is not enough interaction between the subtree tonicity and the rest of the model.
- The analogue of subtree tonicity is the subtree complexity. Notice that subtree complexity is directly affected by three information sources at each subtree: edge complexity, subtree complexities of its children, and local tonicity scores obtained from subtree tonicity.
- Compare that to the active information sources that affect subtree tonicity: subtree tonicities of its children and global tonicity context. There is a very indirect recursion from the aggregation of tree complexities that affects the global tonicity context which in turn affects the subtree tonicities, but this only happens once every update step, rather than at every node traversal.
The meaning of "tonicity" is not consistently interpreted. For individual notes, tonicity is the probability of that note being interpreted as the root, but subtree tonicity is defined as the sum of global tonicities, but it doesn't make sense for an entire subtree to "be a root". When interpreted mathematically, the sum of global tonicities of notes in a subtree is equal to the probability of the root being contained in that subtree. The current flawed algorithm uses "the probability of the root being contained in a subtree" to weight the complexity contribution of that subtree .
# Decoupling likelihood, tonicity, and complexity
To glean some remedies from the first weak spot, recall that the rationale for weighting edge complexity more than subtree complexity was to discourage preferring interpretation trees whose roots are "dissonant offenders", i.e., notes that have high dyadic complexity with respect to many other notes in the voicing. E.g., consider the C-E-G triad interpreted two ways:
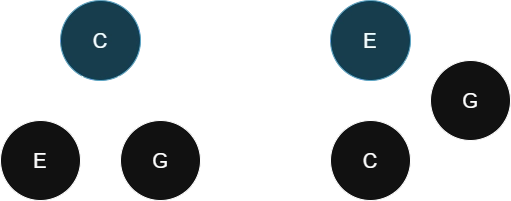
The first interpretation (left) will have the same complexity score whether we penalize edges or subtrees more, since both E and G are leaf nodes.
The second interpretation (right), however, will have a much higher complexity score if we give edge complexity precedence, since the first edge is E->G (m3) which is the highest-complexity dyad out of the three options (P5, M3, m3). Naively, I thought this was good since I did not want E to be considered a root. However, this also means that even though a subtree contains many more edges than a single edge, that single edge's complexity can override the entire subtree's complexity, which is not desirable.
Instead, if we give subtree complexity more precedence, we encounter a new problem: the second interpretation will have a lower complexity score, even lower than the first interpretation, since the subtree G->C is the lowest complexity dyad (P5) out of all three options, which cancels out the high edge complexity of E->G.
Neither of these options help to directly increase the likelihood of the first (left) interpretation without collaterally affecting other interpretations.
The underlying problem is that this model directly conflates complexity, root tonicity, and likelihood of trees. If we didn't have this direct relationship, there would be no need to fine-tune the complexity scores of each tree structure to yield the "correct" choice of root.
Note
Remember back in Generalizing: Polyadic tonicity evolving with time where I mentioned to ignore the modelling of likelihood of interpretation trees? This is now that bad decision coming back to bite.
Note
Likelihood is a statistical term that refers to the probability of observing some data given a model. However, I am not using this word in that rigorous sense, I am just using it as a keyword that refers to "how likely a listener is to perceive this interpretation tree as the model of the chord voicing they heard".
The fix is to decouple likelihood from complexity. Let's forget the current model, and now consider how to recursively compute both the likelihood and complexity of trees. Once we know how to compute the likelihood of a tree, then the tonicity of a note is simply equal to the sum of the likelihood of trees with that note as its root.
Now we have to rework the meaning of subtrees, edges, nodes, tonicity, and complexity in the interpretation tree to include the measure of likelihood. The table below summarizes which terminology applies to which part of the tree:
| Component | Term | Definition |
|---|---|---|
| Node | Global tonicity | Contextual distribution of the probability that node is interpreted as root |
| Edge | Dyadic complexity | Undirected complexity of the dyad formed by the edge |
| Edge | Dyadic tonicity alignment | Higher if parent is "more tonic" than child in a vacuum |
| Subtree | Subtree complexity | Weighted complexity of aggregate of child's subtree complexity & edge complexity |
| Subtree | Subtree likelihood | Likelihood of listener choosing to perceive the chord as this tree |
| Subtree | Subtree tonicity | Sum of global tonicities of all nodes in subtree = probability that perceived root is contained in subtree |
| Subtree | Edge count | Number of edges in subtree (number of nodes - 1) |
Listing ideal behaviours of each component in the new model:
- A subtree with high complexity, regardless of whether the edge that connects it to the parent is simple or complex, should both:
- Contribute more to overall complexity of the tree (compared to simple subtrees), and
- Decrease the overall likelihood of this interpretation tree being a model of how the listener perceives the chord, since the main purpose of having the subtree is to identify consonant substructures.
- Vice versa for low-complexity subtrees.
- An edge with high dyadic complexity, regardless of the subtree (if any) it connects to, should:
- Contribute more to overall complexity of the subtree (compared to simple edges), but
- It should not directly affect the overall likelihood of the listener perceiving this interpretation tree, as some chords/subtrees only have dissonant interpretations. Once the complexity of the entire subtree is computed, that complexity of the whole subtree/tree can be used to determine the likelihood of the subtree/root.
- Vice versa for low-complexity edges.
- An edge with high dyadic tonicity alignment, i.e., the dyadic tonicity of parent-child shows higher tonicity for the parent, should:
- Increase the overall likelihood of this interpretation tree.
- Should not affect complexity.
- Vice versa for low dyadic tonicity alignment.
- A node with high global tonicity alignment, i.e., parent with high global tonicity, or child with low global tonicity, should:
- Increase the overall likelihood of this interpretation tree.
- Vice versa for low global tonicity parents or high global tonicity children.
- To obtain the complexity contribution from each child node, we consider a function of:
- The subtree complexity at that child (from 1. and 5.)
- The dyadic complexity of the edge connecting the parent to the child (from 2.)
- The subtree tonicity (the total probability of the subtree containing the root, which for now we conflate with the "strength" or "tonal gravity" of the subtree)
- The number of nodes in the subtree (to fairly compare between subtrees of different sizes and leaf children)
- We do not include the likelihood of the subtree (to discount the complexity contribution of unlikely subtrees), as that information is already propagated down to the root which weights the final dissonance contribution of the full tree.
- Unlike in the flawed model, the function which weights edge complexity over subtree complexity is now parametrized to allow control over whether and how much edge complexity should affect overall subtree complexity compared to subtree complexity. Ideally, edge complexity should still have more effect than subtree complexity, since edges close to the root of the interpretation tree are the first to be perceived (the model assumes that the pre-order traversal of the interpretation tree represents the order of note perception).
- To obtain the likelihood contribution from each child node, we consider a function of:
- The likelihood of the subtree at that child (from 1. and 6.)
- The dyadic tonicity alignment of the edge connecting the parent to the child (from 3.)
- The global tonicity of the parent and child nodes. (from 4.)
This automatically solves the second weak spot: the subtree tonicity now has a clear purpose, and cross-interaction between dyadic tonicity and complexity is established through the likelihood computation.
The third weak spot is also resolved since tonicity is now consistently defined as the probability of being root for individual notes, and the probability of containing the root for subtrees. Tonicity is no longer conflated with likelihood, which is a separate metric.
# Dyadic complexity model update: Widening major vs. minor complexity score gap
In the first version, I used the dyadic roughness/complexity scoring system as per Base case: Dyadic complexity:
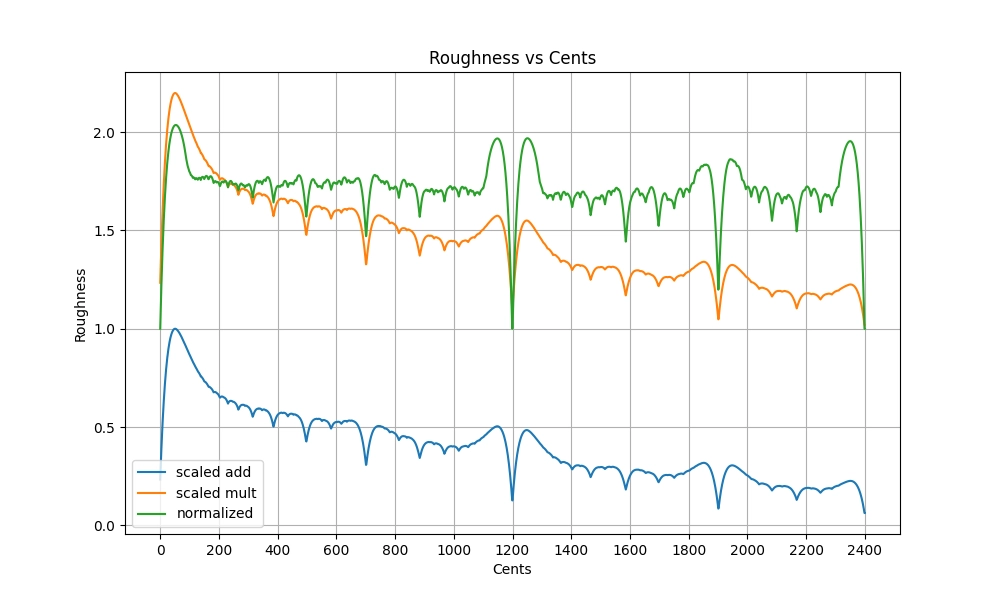
One of the key goals was to ensure major and minor triads did not have the same dissonance score, which is a common problem amongst dyad-based complexity/dissonance models. I've ascertained that minor and major triads are treated differently by this v2 model, but the gap between minor and major triad complexity in various inversions/voicings was abysmally small ( ), relative to the gap between the perfect fifth and fourth dyads. Initially I thought that there was an issue with the polyadic algorithm itself, but I later realized that the bottleneck was not the polyadic algorithm but the original dyadic base case we started with.
The first issue I realized was that, since I was performing most of the tests in 12edo, a lot of the dyadic roughness and tonicity values were not as distinct as I wanted, as the 12edo intervals stray far from the regions of consonance in the roughness curve in the image above, especially for the 5-limit major/minor thirds.
The second issue was that the smoothing model that I used (computing Sethares' roughness every 0.05 cents and averaging each 1-cent bucket) had two flaws:
- It did not model how human interval perception has larger tolerances for simpler intervals
- The uniform average of each 1-cent bucket did not do sufficient smoothing and the roughness curve had very tight tolerances for what it considered "close" to a consonant JI interval.
To solve these issues, I took a -cent sliding window weighted average of the half-cent resolution roughness curves (which were uniformly averaged from the 1/20th-cent resolution roughness curves). Each 1/2 cent in the sliding window was weighted by a Gaussian kernel with , multiplied by to increase the weight of lower-roughness intervals.
I also increased the smoothing on the dyadic tonicity curve so that dyadic tonicities more closely resemble human perception for tolerance of detunings around consonant JI intervals.
The resulting dyadic roughness and tonicity curves are as follows:
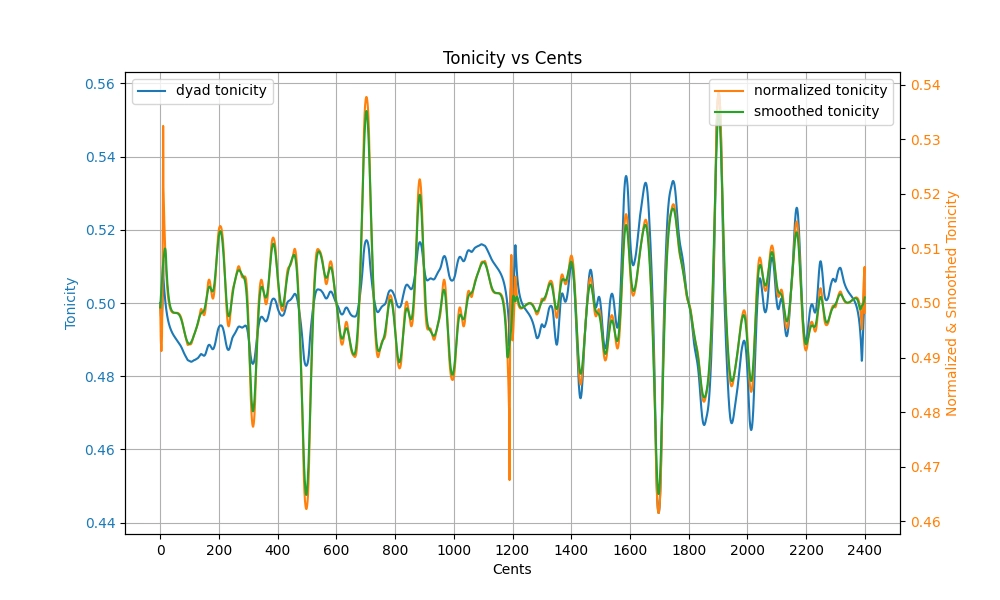
The final dyadic roughness calculation for intervals uses the blue line (scaled add) in Roughness vs Cents, while reducing the per-octave dropoff to 0.86 per octave instead of 0.5 as pictured in the graph (as in, every octave the roughness halves). Additionally, lower interval limit was emulated on a per-dyad basis in lower_interval_limit_penalty() in polyadic.rs.
The normalized dyadic roughness (green) in Roughness vs Cents is used for computing the raw dyad tonicity (blue line in Tonicity vs Cents). The final dyadic tonicity scores are retrieved from the smoothed tonicity (green line in Tonicity vs Cents).
The full 9 octaves of values can be found in sethares_roughness_31_5_0.95.csv and dyad_tonicity_19_5_0.95.csv.
# Information flow of revised model
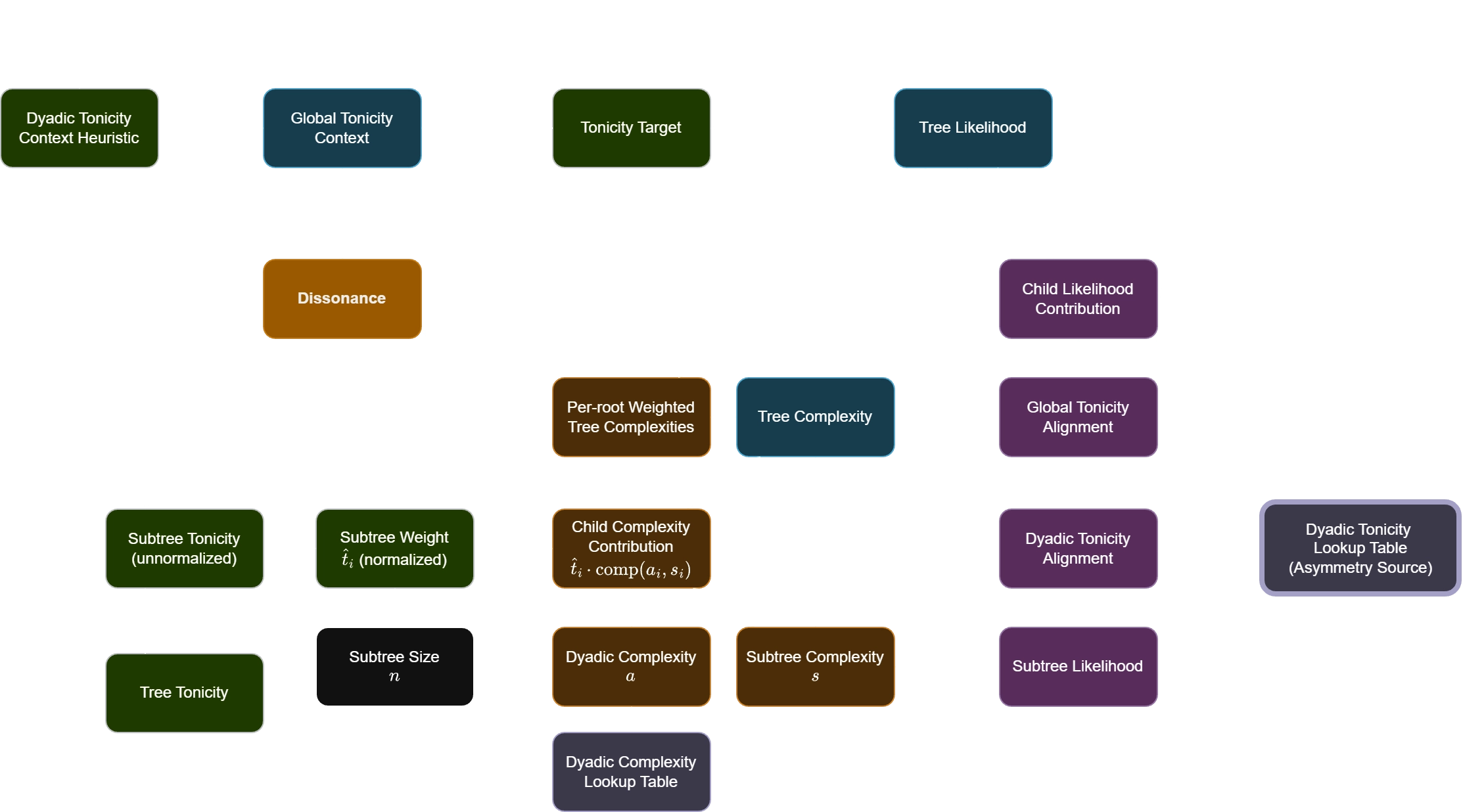
# Computing values in revised model
The adjustable parameters below can be found and modified near the top of polyadic.rs, which implements this algorithm.
# Computing tree/subtree complexity
Tree/subtree complexity of the subtree at node is implemented in compute_child_subtree_complexity_contribution() and compute_child_leaf_complexity_contribution(). It is recursively computed in terms of the -th child's subtree weight ,dyadic complexity between its child and itself , and child's subtree complexity using:
The function is updated from the prior model to include a parameter EDGE_OVER_SUBTREE_COMPLEXITY_BIAS which controls how much more edge complexity should affect overall subtree complexity compared to subtree complexity. A value of means edge complexity has more precedence, i.e., comp(1, 0) = 0.75 but comp(0, 1) = 0.25, and means subtree complexity has more precedence. Since we model interpretation trees as the structure of how the listener perceives the chord from the root to leaves (in pre-order traversal where each node's children are sorted in ascending pitch order), edges closer to the root should have more effect on overall complexity, so EDGE_OVER_SUBTREE_COMPLEXITY_BIAS is initially set to 0.65:
This desmos graph visualizes how behaves for different values of .
At each subtree, the complexity is a value between which represents the minimum and maximum possible complexity attainable. The final complexity score of the tree is the model's dissonance score. See also: the distribution of dissonance scores for -note chords.
# Computing subtree weight
Subtree weight of the -th child of is computed in compute_subtree_weights() as such: For each child node, the child's subtree tonicity (sum of its nodes' tonicities) is computed. Each child has a local tonicity weight according to its subtree tonicity which is given by the softmax over all children's subtree tonicities, with temperature (inverse opinionatedness) parameter initially set to LOCAL_TONICITY_TEMP = 0.7. Let denote the softmax local tonicities of the -th child, such that .
The subtree weight now balances the softmax local tonicities with the proportion of nodes in the subtree at the -th child, so that large subtrees with the same subtree tonicity as small subtrees will still have higher weight. The importance of local tonicity vs. subtree size is controlled by TONICITY_BIAS initially set to 0.6:
where is the number of nodes amongst all child subtrees of .
# Computing tree/subtree likelihood
Tree/subtree likelihood of the subtree at node is computed in compute_child_likelihood_contribution(). It is done recursively in terms of subtree likelihoods of its children inversely weighted by child subtree complexity , dyadic tonicity alignment of the edge from to each child , and global tonicities of node and each child , and is computed by the geometric mean of the likelihood contributions over each child node/subtree:
This likelihood is a multiplicative score in where 1.0 is neutral (neither increasing nor decreasing likelihood).
The first component captures the likelihood of the child subtree scaled inversely by how complex it is. Intuitively, the more complex a subtree, the less its likelihood should affect the likelihood of the full interpretation tree, which is modelled by raising the child subtree's likelihood to the power of a term where COMPLEXITY_LIKELIHOOD_SCALING which increases the weight of the child subtree's likelihood if the complexity is low. Then, two bias terms are multiplied: one that increases the likelihood by up to times if the subtree complexity is low, and the other parameter DEEP_TREE_LIKELIHOOD_PENALTY which decreases the overall likelihood of deeply nested interpretation trees by scaling likelihood of each child subtree by :
COMPLEXITY_LIKELIHOOD_SCALING is initially set to 2.0, COMPLEXITY_LIKELIHOOD_BIAS to 1.5 and DEEP_TREE_LIKELIHOOD_PENALTY set toThe second component is the dyadic alignment of the edge from parent to child , computed from the dyadic tonicity which represents how tonic the parent is when the parent and child notes are played in a vacuum. This value is retrieved from the lookup table as obtained in Base case: Dyadic tonicity. Contribution of dyadic alignment is scaled by DYADIC_TONICITY_LIKELIHOOD_SCALING initially set to 4.0:
Finally, the third component is the global tonicity alignment of parent and child , computed the logistic function applied to the ratio between their global tonicities . This contribution is scaled by GLOBAL_TONICITY_LIKELIHOOD_SCALING initially set to 4.0:
# Computing final dissonance score
The dissonance score is computed by the weighted sum of complexities of each interpretation tree, weighted twice, first by the aggregated softmax likelihoods of interpretation trees, and then by the probability of perceiving each root according to the updated global tonicity context (after updating tonicities towards the target). A softmax with low temperature TONICITY_CONTEXT_TEMPERATURE_DISS is applied on the global tonicity context to model how a listener would rather perceive one root at a time, rather than multiple roots simultaneously.
trees(r) is the set of interpretation trees rooted at note , is the complexity of tree , is the softmax likelihood of tree amongst all interpretation trees (with temperature TONICITY_CONTEXT_TEMPERATURE_TARGET), and is the sum of all softmax tree likelihoods rooted at note .This double-weighting ensures that both the most likely interpretation trees for each root, and trees with the most likely perceived root will have a stronger influence on the final dissonance score.
# Computing tonicity target
The target global tonicities are computed by the softmax of likelihoods of each interpretation tree, with temperature TONICITY_CONTEXT_TEMPERATURE_TARGET.
# Algorithm v2 results (pre-optimization & tuning)
I have run some initial tests with
Code
cargo test polyadic::tests::test_graph_diss -- --exact --no-capture > test_graph_diss.txt
cargo test polyadic::tests::test_sanity_metrics -- --exact --no-capture > test_sanity1.txt
Using the following parameters:
Code
const HEURISTIC_DYAD_TONICITY_TEMP: f64 = 0.8;
const LOCAL_TONICITY_TEMP: f64 = 0.7;
const NEW_CANDIDATE_TONICITY_RATIO: f64 = 0.2;
const EDGE_OVER_SUBTREE_COMPLEXITY_BIAS: f64 = 1.0;
const TONICITY_BIAS: f64 = 0.6;
const COMPLEXITY_LIKELIHOOD_BIAS: f64 = 1.5;
const COMPLEXITY_LIKELIHOOD_SCALING: f64 = 1.0;
const DEEP_TREE_LIKELIHOOD_PENALTY: f64 = 2.2;
const GLOBAL_TONICITY_LIKELIHOOD_SCALING: f64 = (2u128 << 12) as f64;
const DYADIC_TONICITY_LIKELIHOOD_SCALING: f64 = (2u128 << 38) as f64;
const LOW_NOTE_ROOT_LIKELIHOOD_SCALING: f64 = 1.04;
const TONICITY_CONTEXT_TEMPERATURE_TARGET: f64 = 0.5;
const TONICITY_CONTEXT_TEMPERATURE_DISS: f64 = 0.1;
Note
The full results from this initial test can be found in paper/test_graph_diss.txt and paper/test_sanity1.txt.
The test function graph_diss() has adjustable parameters that control how much information is displayed. Currently, only the top 2 likelihood and lowest 2 complexity trees are displayed per root, and the overall top 10 dissonance contributing trees are displayed for each chord voicing.
I have only kept the important metrics in the examples below, so I recommend exploring the test results or running your own tests.
# Sanity metrics
Sanity metrics checks the basic requirements of the algorithm:
Code
=============== SANITY METRICS ================
min - maj: 0.019264974173406557
min - maj scaled: 0.42895460445340416
tritone - p4: 0.06729656027850978
p4 - p5: 0.10898553770569647
lower intv. lim: 0.13554630263072426
P5 tonicity gap: 0.559810129798844
targ. C conf maj: 0.49758471909992175
targ. C conf min: 0.45966830181957113
min - maj: The absolute dissonance score gap between the minor and major triad in root position.- This value means that a minor triad scores 0.019 higher dissonance than a major triad, which is a good sign that the model can distinguish between major and minor triads.
min - maj scaled: The ratio between the min-maj triad dissonance gap and the gap between the dissonance score gap between minor 3rd and major 3rd dyads.- Since the polyadic model uses dyadic roughness as the base source of complexity, a value of 1 here would mean that the polyadic model is maximally efficient at translating the difference between a minor and major dyad into the difference between the minor and major triads. A score of 0.43 here means that it is able to capture 43% of that difference, which I am satisfied with.
tritone - p4: The dissonance of a tritone minus the dissonance of a perfect fourth.- There was a bug when developing this revised model where the P4 scored higher dissonance than the tritone, which is obviously wrong. This bug turned out to be a math mistake in the double-weighted final complexity calculation, which has now been fixed. A positive value here is a good sign.
p4 - p5: The dissonance of a perfect fourth minus the dissonance of a perfect fifth. With certain badly-set parameters, this value could be too small or too large caused by exaggerated effects of global tonicity on the complexity scoring. A value that is close to the difference between P4 and P5 in the raw (scaled add) dyadic complexity in the Roughness vs Cents graph above is a good sign.lower intv. lim: The difference in dissonance score between the same A major chord played at A7 and played at A1. This value should be positive, and higher scores denote a larger effect of the lower interval limit penalty on the overall dissonance score. This value is very subjective, so it should be tuned on a per-use-case basis.P5 tonicity gap: The difference between the target tonicity of the root and fifth of the perfect fifth dyad. A higher value means that the model is more confident that the root is more tonic than the fifth in a perfect fifth dyad. Amongst all dyadic options, the P5 has the largest dyadic tonicity score, so this value gives an approximate upper bound on the maximum confidence ( ) that any one note in the chord is tonic, without additional context.targ. C conf maj: The target tonicity of C in the C major triad. A higher value means that the model is more confident that C is the root of the C major triad.targ. C conf min: The target tonicity of C in the C minor triad. A higher value means that the model is more confident that C is the root of the C minor triad.- In the old version of this project (before this article was written), the model would say Eb is the root of the C minor triad. This is not exactly wrong (because relative major), but according to intuition, in a vacuum, the perfect fifth C-G's likelihood contribution to C as root should outweigh the major third between Eb and G, which this model is now able to capture.
Note
After some optimizations & more tuning, I ran a larger set of tests: see Algorithm v2 results post-optimization/tuning
# Practical considerations
# Adding & removing notes
The lattice visualizer is a real-time visualization for this complexity & tonicity algorithm, with the goal of detempering MIDI input played in any equal temperament in real-time.
Unlike other models of harmonic analysis that rely on only notes that are currently being sounded/played, I wanted to incorporate the role of auditory memory in harmonic perception. Thus, the visualizer also models a short-term memory of notes that are played, where the strength/persistence of those notes increase with tonicity, volume (midi velocity), repetition, recency, and other supporting octaves.
The exact implementation is beyond the scope of this article, but in a nutshell, a maximum of 8 notes in the contextual memory is maintained. Each note has a persistence score such that when it gets to 0, the note is removed from memory. The persistence of each note is computed using its tonicity and also its dissonance contribution (i.e., the difference of complexity when this note is present vs absent). The persistence score also determines which note is the first to go when the max number of notes is exceeded. Ideally, there should be no maximum limit on the number of notes, however, this was necessary to keep the computation manageable for real-time performance.
Note
I am still not yet fully satisfied with the pitch memory model. Right now it is over reliant on the dissonance and tonicity scoring system of this algorithm, but this causes it to be limited to too few notes. I am considering eventually implementing a decoupled pitch memory model based on something like A Dynamical Model of Pitch Memory (Kim Ji Chul) and Short Term Memory for Tones (Diana Deutsch)
When a new note is played that is not already in the pitch memory model (and also not an octave-equivalent of an existing note), the visualizer goes through a pre-computed list of possible JI ratio interpretations to perform real-time detemperament. These various interpretations are sent as candidate frequencies to this algorithm, where each candidate is assessed as the -th note. The new candidate will be initialized with an initial tonicity score proportionate to the average-of-dyads heuristic in First step: Major vs minor triads.
Question
How to improve the initial tonicity assignment of new candidates, especially so that the existing tonicities of notes are not too affected?
Besides initializing as the heuristic value, I have also tried initializing it to some small value like 0.001. Both seemed to end up with similar results in my experiments playing around with the visualizer.
Then, the "best candidate" will be picked, which is scored on a heuristic that depends on its dissonance contribution, JI complexity relative to the current tonal center/harmonic centroid in 5D space of 11-limit JI, and its tonicity, in descending order of precedence. The selected candidate is then added to the pitch memory model.
# Optimizations
I would be happy if the algorithm could run as is. The problem now is that the computational complexity explodes exponentially with the number of notes. If I have 7 notes in the pitch memory model and I am playing one new note, the algorithm has to consider all possible interpretation trees with 8 notes, multiplied by the number of candidate frequencies for the new note (which can be up to 20). This gives a maximal complexity of performing a DFS on trees per update tick.
This complexity is already an improvement over the previous version of the algorithm in polyadic-old.rs that grew factorially with the number of notes, the previous algorithm would have to consider trees for a full search.
The full tree generation code is found in gen_sts() of tree_gen.rs, where I used a root-down approach with a combinatorial choosing function to enumerate possible children for each node. It turns out that generating the set of all spanning trees under the optimizing constraints below is not a trivial algorithm.
The following heuristic optimizations are currently implemented to reduce the interpretation tree search space while still holding true to my musical intuition. Note that these optimizations do not require computing any complexity or tonicity values, but only depend on the structure of the interpretation tree itself.
# Max tree depth
Any path of from the root to leaf in an interpretation tree represents a chain of relative references the listener will interpret the notes as.
For example, in the depth-3 tree below:
The path from C4 to B4 implies an interpretation where the listener chooses to hear B4 as the fifth of E4 as the minor third below G4 as the fifth of C4.
Intuitively, there would be no reason for a listener to interpret this chord in such a convoluted way. Instead, something more intuitive would follow the natural construction of Cmaj9 where fifth-extensions are stacked on the root and third, which yields a depth-2 tree:
There are some edge cases of extremely complex large chords where deep interpretation trees are intuitive, but (to my subjective intuition), most interpretation trees are within a depth of 3 (i.e., where the root is depth 0, the deepest leaf node is the great-grandchild of the root).
This optimization is parametrized by the max_depth parameter of gen_sts().
# Max siblings
Another intuitive optimization is to limit the number of children (or equivalently, siblings) each node can have. Take for example the following tree:
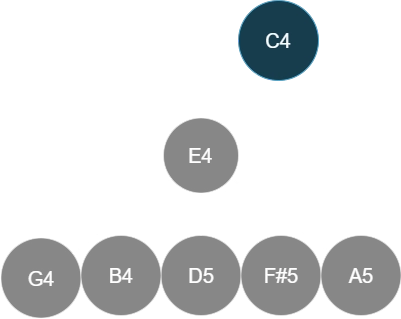
It is unlikely for a listener to interpret 5 notes all with respect to a non-root E4. In this case we have a Cmaj13#11 chord represented as a tertian stack, so the following interpretations would be more intuitive for me:
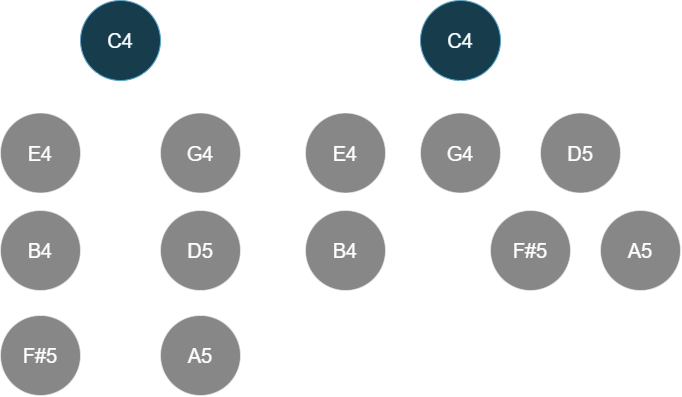
I find that 3 children per node is a reasonable limit for most interpretations.
This optimization is parametrized by the max_siblings parameter of gen_sts().
# Pre-order traversal inversions
There is an intuitive ordering of trees that decided whether a tree "made sense" or not, even without evaluating complexity or tonicity. This took some time for me to realize and formalize.
Compare the following two interpretations of the same voicing of the chord Cmaj13#11:
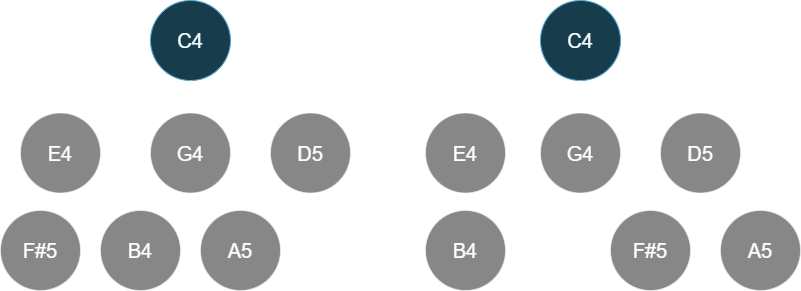
Both trees have the same structure and the same root, the root has three children, one with no children, one with one child, and one with two children; both trees' nodes' children are sorted in increasing pitch order visually from left to right, and both trees have relatively consonant intervals between parent and child nodes.
However, one tree "made more sense". At least for me, that was the right tree.
The notes of the voicing, in order of ascending pitch, is C4 E4 G4 B4 D5 F#5 A5, which is the standard tertian stack for Cmaj13#11.
However, the left tree feels "all over the place". My intuition told me it had something to do with how notes want to be perceived in order of bottom to top. I.e., lower notes are more likely seen as the parents of higher notes (because we naturally hear higher notes relative to lower notes), and the children of lower notes should rarely be higher than the children of higher notes. E.g., F#5 is the child of E4 and B4 & A4 are children of G4, but E4 is lower than G4, yet F#5 is higher than B4 and A4.
Initially I thought that this was only due to the tertian nature of the voicing, so I tried this experiment with another common voicing: C4 C#4 E4 G4 A4 C5, which is relatively common closed voicing for C13b9:
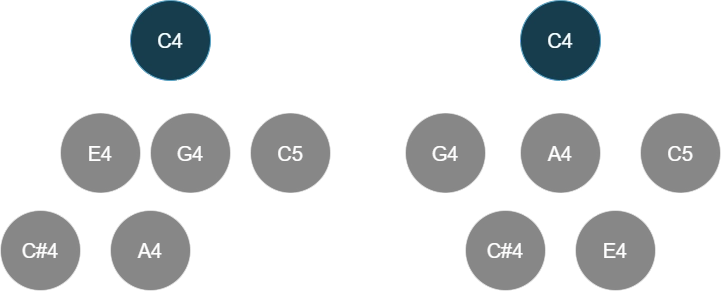
There is only one difference between the two trees: the position of E4 and A4 are swapped (and the children of C4 are sorted in ascending pitch as usual). Both trees still preserve the A major substructure of the voicing as a subtree.
Yet, the left tree feels more slightly more coherent than the right tree.
I realized that the pre-order traversal of the tree closely matches how a human would perceive the interpretation organized in a tree structure.
In the left tree of the previous Cmaj13#11 example, the pre-order traversal is C4, E4, F#5, G4, B4, A5, D5. The right tree for Cmaj13#11 has pre-order traversal C4, E4, B4, G4, D5, F#5, A5.
In music terminology, the left tree models the interpretation of that Cmaj13#11 voicing as:
- C4 is the root
- E4 is the 3 of the root
- F#5 is the 9 of E4
- G4 is the 5 of the root
- B4 is the 3 of G4
- A5 is the 9 of G4
- D5 is the 9 of the root
The right tree for Cmaj13#11 models the interpretation as:
- C4 is the root
- E4 is the 3 of the root
- B4 is the 5 of E4
- G4 is the 5 of the root
- D5 is the 9 of the root
- F#5 is the 3 of D5
- A5 is the 5 of D5
Claim 1: Pre-order traversal of the tree gives an order of precedence of notes. Notice how if we perceive sibling nodes in ascending pitch order, we end up with a natural order of pitch perception in pre-order traversal. Of course, the biggest counter-example would be the fact that the lowest and highest pitches are perceived first in practice. However, the intuition of constructing how notes relate to each other still holds when hearing in terms of vertical harmony.
Claim 2: The intuitive "weirdness" of tree comes from inversions of the pre-order traversal when compared to the pitch-order of the voicing. Given an original ordering of notes from low to high, the number of inversions is the number of pairs of notes such that but appears after in the pre-order traversal of the tree.
Important
These claims are merely hypotheses. They come from testing my intuition on a few examples, but I would like to know if there are any more rigorous ways to justify these, or if there are any counter-examples.
Going back to the Cmaj13#11 example, the left tree's pre-order (C4, E4, F#5, G4, B4, A5, D5) has 4 inversions when compared to pitch-order:
- (F#5, G4)
- (F#5, B4)
- (F#5, D5)
- (A5, D5)
Whereas, the right tree's pre-order (C4, E4, B4, G4, D5, F#5, A5) has only 1 inversion:
- (B4, G4)
In the second example with the closed C13b9 chord, the left tree's pre-order (C4, E4, C#4, A4, G4, C5) has 2 inversions:
- (E4, C#4)
- (A4, G4)
But the right tree's pre-order (C4, G4, A4, C#4, E4, C5) has 4 inversions:
- (G4, C#4)
- (G4, E4)
- (A4, C#4)
- (A4, E4)
Working through more of these examples gave me more confidence that limiting the number of inversions in pre-order traversal would help prune the search space of interpretation trees in a way that prioritizes more intuitive interpretations while still being very computationally efficient.
Note
So far, all the previous examples use the bottom note as the root of the interpretation tree.
If we consider inversions of the root of the tree (which is the first node in the pre-order traversal), then making the highest-pitched note a root of the tree will prune all trees for chords with more than max_inversions notes, since every note will be an inversion of at least the root.
Since we require equal exploration of interpretation trees for each root (to compute the relative tonicities fairly based on per-root aggregated complexity scores), the inversion count should not consider the first node in the pre-order traversal, i.e., any inverted pairs involving the root note of the interpretation tree should not be counted.
As a guideline for the maximum number of inversions allowed, I considered the following interpretation of Cmaj13#11:
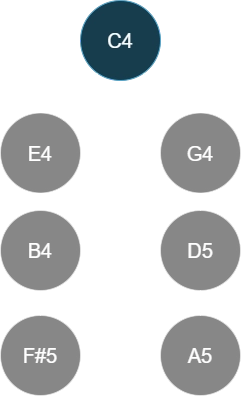
The pre-order traversal is C4, E4, B4, F#5, G4, D5, A5, which has 3 inversions:
- (B4, G4)
- (F#5, G4)
- (F#5, D5)
Thus, I have used max_inversions = 3 for spanning tree generation in gen_sts().
# Tree-generation pruning results
Before pruning, there are a total of unique spanning trees (counting unique choices of root). The tabulation shows the trees before and after pruning:
| Number of notes | Total trees before pruning | Total trees after pruning |
|---|---|---|
| 2 | 2 | 2 |
| 3 | 9 | 9 |
| 4 | 64 | 64 |
| 5 | 625 | 400 |
| 6 | 7776 | 1,842 |
| 7 | 117,649 | 6,972 |
| 8 | 2,097,152 | 23,104 |
# Tree generation
The algorithm for enumerating all possible spanning trees within the above constraints was not trivial. The full implementation is in tree_gen.rs in the gen_sts() function (where gen_sts_recursive is doing the bulk of the work).
Most spanning tree generation algorithms are leaf-up, i.e., starting from individual unconnected nodes and adding edges between them until all nodes are connected, checking that there are no cycles at each step. This is the main process for other spanning tree algos especially minimum spanning tree algorithms like Prim's and Kruskal's.
However, the leaf-up approach wouldn't work since the bulk of the pruning was done using the pre-order traversal of trees, which meant the root and lower-depth structure had to be fixed in order for early pruning to be done.
The main issue I faced with the root-down spanning tree generation was that there were many orders the same set of edges can be added in. E.g., for just 3 nodes, populating the edges then was regarded as a different tree than then .
To work around this, a queue of visited nodes had to be kept, which tracked which nodes have not yet been assigned children. Each visit to a node would comprise iterating over 0 to the max number of children (i.e., 3), and for each iteration, forming all ascending-order sets of combinations of remaining unvisited nodes, and those will be assigned as children of each possible spanning tree. This happens until all nodes are visited or one of the constraints were broken.
The tree generation process takes around a few seconds and is done at loading time of the WASM module. Unlike the previous version of graph-diss which generated and pruned trees on the fly, I found it much more efficient this time to pre-compute trees first, then iterate over the pre-computed trees.
Pros of pre-computing trees: faster chord evaluation time.
Cons: pruning metrics that depended on algo-specific values (e.g., complexity/likelihood of subtree) cannot be used for additional computation speedup, so the algorithm could not choose which trees to discard mid-computation
# Memoization of DFS across interpretation trees
After pruning unlikely interpretation trees, there are still 23,104 trees to evaluate for 8-note chords. Each evaluation involves relatively expensive math computations (exponentials, floating point powers, multiplications) that has to be done over 7 edges per tree. This still adds up to a significant amount of complexity.
I realized that many smaller subtrees were repeated across different interpretation trees. Since the subtree's complexity and likelihood only depends on its nodes, edges, and dyadic roughness/tonicity values, which are all constant throughout the evaluation over all interpretation trees, I used a u64 SubtreeKey that uniquely identifies the subtree at each node of an interpretation tree, such that identical subtrees present in other interpretation trees have the same SubtreeKey. The SubtreeKey is generated efficiently while TREES are being pre-computed at startup.
Using SubtreeKeys, it was simple to implement memoization across computing all DFSs of all possible interpretation trees of an input chord.
A benchmark was run on 201 iterations of an 8-note tonicity context update.
Without memoization:
Code
=============== SANITY METRICS ================
min - maj: 0.012137977573400405
min - maj scaled: 0.2702646430769437
tritone - p4: 0.06729656027850967
p4 - p5: 0.10898553770569636
lower intv. lim: 0.13439663775500937
P5 tonicity gap: 0.36668470251115715
targ. C conf maj: 0.42407330546463173
targ. C conf min: 0.40488250923758157
existing vs cand: 0.011043448871907446
Benchmark time (201 8-note iters): 71.6581382 seconds
With memoization:
Code
=============== SANITY METRICS ================
min - maj: 0.012137977573400405
min - maj scaled: 0.2702646430769437
tritone - p4: 0.06729656027850967
p4 - p5: 0.10898553770569636
lower intv. lim: 0.13439663775500937
P5 tonicity gap: 0.36668470251115715
targ. C conf maj: 0.42407330546463173
targ. C conf min: 0.40488250923758157
existing vs cand: 0.011043448871907446
Benchmark time (201 8-note iters): 7.02643 seconds
After memoization, an 8-note tonicity update computation is performed in 35ms on average.
Note that all sanity metric scores were unaffected by the memoization.
The test tree_gen::tests::test_subtree_key_uniqueness ensures that all subtree keys were unique and well-formed.
Code
Checking 2 trees with 2 nodes
Checking 9 trees with 3 nodes
Checking 64 trees with 4 nodes
Checking 400 trees with 5 nodes
Checking 1842 trees with 6 nodes
Checking 6972 trees with 7 nodes
Checking 23104 trees with 8 nodes
Subtree Key Statistics:
Total unique keys: 41564
Total unique subtrees: 41564
Duplicate subtrees found (expected): 205411
Collisions found (should be 0): 0
In total, only 41564 unique subtrees exist amongst all interpretation trees of up to 8 notes. This means that even though there are 23,104 unique interpretation trees for 8-note chords, totalling 184832 subtrees with repeats, the amount of (sub)tree-traversal computations that have to be done is limited to at most 41564, and the rest of the computations can be reused for an expected 4.4x speed up.
# Memoizing with hot-swap candidate note
When testing candidate frequencies, only one node is assigned a different frequency & heuristic tonicity score. Hence, all subtrees that do not contain the candidate node can have their complexity and likelihood values reused from the previous candidate evaluation.
However, since the SubtreeKey indexes nodes based on ascending pitch, when the candidate frequency is changed, the ordering of nodes may change, which will cause the same subtree (with respect to note frequencies) show up as a different pre-computed SubtreeKey.
Hence, to allow for memoizing repeated calculations over different candidate notes, the pre-computed subtree keys had to be transformed via polyadic::remap_subtree_key_to_og_indexing(), which remaps subtree keys from ascending-pitch indexing to the indexing as per freqs passed to graph_dissonance(), and the candidate note is assigned to the last index.
The following test benchmarks the evolution of tonicity scores over 500 iterations of updating the tonicities of 6 existing notes + 10 choices of candidate notes.
Code
Bench iter 0: max tonicity cands idx: 3, tonicities: [0.16282858618467694, 0.16171231622828977, 0.16070448093331896, 0.16251010312599934, 0.1610516490358855, 0.16212473363546345, 0.02906813085636607]
Bench iter 25: max tonicity cands idx: 3, tonicities: [0.16550653749099487, 0.16119398261722512, 0.15929013638808595, 0.16253286081456372, 0.16000648157205105, 0.1615350775845235, 0.029934923532555703]
[omitted...]
Bench iter 450: max tonicity cands idx: 3, tonicities: [0.2621828224947987, 0.14391759268167806, 0.1330964841239457, 0.150881676576002, 0.1372819651756823, 0.14275591308535807, 0.02988354586253526]
Bench iter 475: max tonicity cands idx: 3, tonicities: [0.26989367046940826, 0.14241808444092754, 0.13144808174396425, 0.14948954952504634, 0.13568187509118296, 0.1411840793299383, 0.029884659399532346]
Benchmark time (500 7-note 10-candidate iters): 42.2349836 seconds
This sums up to around 84ms latency per new note played for testing 10 possible candidates.
Running this test again with 20 candidate notes each iteration:
Code
Bench iter 0: max tonicity cands idx: 3, tonicities: [0.16282858618467694, 0.16171231622828977, 0.16070448093331896, 0.16251010312599934, 0.1610516490358855, 0.16212473363546345, 0.02906813085636607]
Bench iter 25: max tonicity cands idx: 3, tonicities: [0.16550653749099487, 0.16119398261722512, 0.15929013638808595, 0.16253286081456372, 0.16000648157205105, 0.1615350775845235, 0.029934923532555703]
[omitted...]
Bench iter 450: max tonicity cands idx: 3, tonicities: [0.2621828224947987, 0.14391759268167806, 0.1330964841239457, 0.150881676576002, 0.1372819651756823, 0.14275591308535807, 0.02988354586253526]
Bench iter 475: max tonicity cands idx: 3, tonicities: [0.26989367046940826, 0.14241808444092754, 0.13144808174396425, 0.14948954952504634, 0.13568187509118296, 0.1411840793299383, 0.029884659399532346]
Benchmark time (500 7-note 20-candidate iters): 73.4741993 seconds
For 20 candidates tested, the algorithm takes 147ms. We doubled the number of candidates, but the computation time only increased 75%, so the memoization across candidates is working well.
# Random tree sampling
Despite pruning and memoizations (and other optimizations not documented above), the algorithm takes an unacceptable amount of time to evaluate candidates on 7-note chords. The goal is sub-16ms delay per note played (where the algo has to decide which detemperament candidate to accept), and sub 5ms for 7-note tonicity updates. I decided to limit the maximum number of interpretation trees to evaluate, randomly sampling if the number of pre-computed trees exceeds the limit.
To find the optimal tradeoff between speed and accuracy, I ran the following benchmark in polyadic::tests::bench_max_trees_deterioration, which tests how different the result of N iterations of a 6-note + 10-candidates is while varying the MAX_TREES parameter. Note that when more iterations are run, the tonicity scores will have had more time to converge, so the lower the MAX_TREES setting, the more opinionated the tonicity scores will be. I am simply checking that the overall relative order of tonicity scores between the notes remain similar.
Code
=== MAX_TREES = 18446744073709551615 ===
Benchmark time (142 6-note 10-candidate iters): 10.0458476 seconds. (14.13519353011089 iter/sec)
Max tonicity candidate: 3 (1700.00c). dissonance: 0.5377339992333904, tonicity: [0.18002023084205093, 0.15909286025132283, 0.15348772368029945, 0.1627118860164894, 0.15570388852891154, 0.1590510041130048, 0.029932406567921024]
Tonicity ranking of candidates: [0, 3, 1, 5, 4, 2, 6]
=== MAX_TREES = 20000 ===
Benchmark time (141 6-note 10-candidate iters): 10.0429054 seconds. (14.039761840234002 iter/sec)
Max tonicity candidate: 3 (1700.00c). dissonance: 0.5377248849132501, tonicity: [0.17988104210798891, 0.15911441671002594, 0.1535377764579727, 0.16271555544482016, 0.15574258658603835, 0.1590761689179511, 0.029932453775202872]
Tonicity ranking of candidates: [0, 3, 1, 5, 4, 2, 6]
=== MAX_TREES = 10000 ===
Benchmark time (143 6-note 10-candidate iters): 10.0016052 seconds. (14.29770493240425 iter/sec)
Max tonicity candidate: 3 (1700.00c). dissonance: 0.537743152470425, tonicity: [0.18015974449432864, 0.15907122728341352, 0.15343765623120897, 0.1627081070922976, 0.15566514757696204, 0.1590257585359457, 0.02993235878584358]
Tonicity ranking of candidates: [0, 3, 1, 5, 4, 2, 6]
=== MAX_TREES = 5000 ===
Benchmark time (191 6-note 10-candidate iters): 10.058831 seconds. (18.98828999115305 iter/sec)
Max tonicity candidate: 3 (1700.00c). dissonance: 0.5388464356796752, tonicity: [0.1873567890717728, 0.15795377500250674, 0.15083581733682216, 0.1624595756792588, 0.1538692797671602, 0.15759126795717118, 0.029933495185308075]
Tonicity ranking of candidates: [0, 3, 1, 5, 4, 2, 6]
=== MAX_TREES = 2500 ===
Benchmark time (361 6-note 10-candidate iters): 10.0012688 seconds. (36.095420213083365 iter/sec)
Max tonicity candidate: 3 (1700.00c). dissonance: 0.5399485224283189, tonicity: [0.22648247107949723, 0.15057484092925466, 0.1406736027833574, 0.15719734148624004, 0.14485563487531183, 0.150343861560041, 0.029872247286297768]
Tonicity ranking of candidates: [0, 3, 1, 5, 4, 2, 6]
=== MAX_TREES = 1000 ===
Benchmark time (500 6-note 10-candidate iters): 6.0210256 seconds. (83.04233086137351 iter/sec)
Max tonicity candidate: 3 (1700.00c). dissonance: 0.5469606224618418, tonicity: [0.27849698437218057, 0.14125546208177422, 0.12764070621062157, 0.14849983663283894, 0.1343111612998853, 0.13991080158169475, 0.029885047821004585]
Tonicity ranking of candidates: [0, 3, 1, 5, 4, 2, 6]
=== MAX_TREES = 500 ===
Benchmark time (500 6-note 10-candidate iters): 3.0749186 seconds. (162.60593044641897 iter/sec)
Max tonicity candidate: 3 (1700.00c). dissonance: 0.5483764583541461, tonicity: [0.26666365549106963, 0.14385612359553135, 0.13195171463371386, 0.15058836097702058, 0.13521524972866156, 0.14182190132065034, 0.029902994253352678]
Tonicity ranking of candidates: [0, 3, 1, 5, 4, 2, 6]
=== MAX_TREES = 250 ===
test polyadic::tests::bench_max_trees_deterioration has been running for over 60 seconds
Benchmark time (500 6-note 10-candidate iters): 1.7087951000000001 seconds. (292.6038352989191 iter/sec)
Max tonicity candidate: 3 (1700.00c). dissonance: 0.5517239352989377, tonicity: [0.271807987828909, 0.14435628360638428, 0.13119516691110594, 0.14745568700369144, 0.13376365921293318, 0.1415701896056374, 0.029851025831338623]
Tonicity ranking of candidates: [0, 3, 1, 5, 4, 2, 6]
=== MAX_TREES = 100 ===
Benchmark time (500 6-note 10-candidate iters): 0.8654707 seconds. (577.7203087291113 iter/sec)
Max tonicity candidate: 3 (1700.00c). dissonance: 0.5390447519117809, tonicity: [0.27181371610930805, 0.14273354756867804, 0.13024009744127812, 0.1500109124773596, 0.13401439691166853, 0.14129491524896157, 0.029892414242746107]
Tonicity ranking of candidates: [0, 3, 1, 5, 4, 2, 6]
In fact, even after removing most of the trees (randomly selecting 100 out of 6972), the most optimal detemperament candidate (1700c), and the relative ranking of tonicities in the dissonance & tonicity evaluation of resultant chord using that candidate remains unchanged!
To err on the side of more accuracy, I have set MAX_TREES = 800 for real-time update of existing chords, and MAX_TREES_CANDIDATES = 4000 which is evenly distributed across the number of candidate frequencies provided (e.g., if 10 candidate frequencies are given, then each candidate will be allowed to evaluate up to 400 trees).
# Algorithm v2 results (post-optimization/tuning)
Using the following parameters:
Code
const HEURISTIC_DYAD_TONICITY_TEMP: f64 = 0.8;
const LOCAL_TONICITY_TEMP: f64 = 0.7;
const NEW_CANDIDATE_TONICITY_RATIO: f64 = 0.2;
const EDGE_OVER_SUBTREE_COMPLEXITY_BIAS: f64 = 1.0;
const TONICITY_BIAS: f64 = 0.6;
const COMPLEXITY_LIKELIHOOD_BIAS: f64 = 1.5;
const COMPLEXITY_LIKELIHOOD_SCALING: f64 = 1.0;
const DEEP_TREE_LIKELIHOOD_PENALTY: f64 = 2.2;
const GLOBAL_TONICITY_LIKELIHOOD_SCALING: f64 = (2u128 << 10) as f64;
const GLOBAL_TONICITY_LIKELIHOOD_MAX_LN: f64 = 1.0;
const DYADIC_TONICITY_LIKELIHOOD_SCALING: f64 = (2u128 << 38) as f64;
const LOW_NOTE_ROOT_LIKELIHOOD_SCALING: f64 = 1.04;
const TONICITY_CONTEXT_TEMPERATURE_TARGET: f64 = 0.8;
const TONICITY_CONTEXT_TEMPERATURE_DISS: f64 = 0.1;
Tip
Guidelines on how to adjust these parameters can be found in the documentation of the parameters in polyadic.rs.
The following tests computed graph_dissonance() where max_trees was unlimited. In real-time mode, these results may be slightly deteriorated.
Performing tests with
Code
cargo test polyadic::tests::test_graph_diss --release -- --exact --no-capture > test_graph_diss_memo.txt
cargo test polyadic::tests::test_sanity_metrics --release -- --exact --no-capture > test_sanity_memoized_cand.txt
cargo test test_context_effect --release -- --no-capture > test_context_effect.txt
The results can be found in test_sanity_memoized_cand.txt, test_graph_diss_memo.txt, and test_context_effect.txt.
# Sanity tests
Note
I have reduced the effect of GLOBAL_TONICITY_LIKELIHOOD_SCALING and capped the maximum (multiplicative) change in likelihood to .
In other tests, the global tonicity alignment contribution to the likelihood score approached asymptotes when one note had too low or global tonicity. The lowered global tonicity scaling and new GLOBAL_TONICITY_LIKELIHOOD_MAX_LN parameter prevents asymptotic behavior where the model is overly confident that only one note is the tonic (nearly 100% tonicity), and the other notes have nearly 0 tonicity. This overconfidence feeds back into the algorithm the next iteration and causes a feedback loop.
For this reason, the minor-major triadic dissonance gap is reduced, since it scales with how confident the model is, i.e., how much higher the "tonic" scores in tonicity than other notes, and reducing global tonicity reduces variance in tonicity scores. This can be partially compensated by decreasing TONCITY_CONTEXT_TEMPERATURE_DISS which increases the confidence of tonicity scores only for the dissonance calculation without affecting the tonicity scores used to feed back into the next iteration.
Code
=============== SANITY METRICS ================
min - maj: 0.012137977573400405
min - maj scaled: 0.2702646430769437
tritone - p4: 0.06729656027850967
p4 - p5: 0.10898553770569636
lower intv. lim: 0.13439663775500937
P5 tonicity gap: 0.36668470251115715
targ. C conf maj: 0.42407330546463173
targ. C conf min: 0.40488250923758157
existing vs cand: 0.011043448871907446
Benchmark time (201 8-note iters): 7.02643 seconds
# 7-note voicings
How to read the results
0.00c, 400.0c, etc... are the note pitches in cents relative to C4 (in this test). For each note, we have:ton: contextual tonicity of this note after one iteration of update, smoothed over time.ton ctx: the initial tonicity values from context (assigned to 0 since we assume no prior context). These values are normalized to sum to 1. If all 0, the model is initialized using the sum-of-dyadic-tonicities heuristic.ton tgt: the target values thattonis being smoothed towards in this iteration.diss raw: the unscaled contribution of dissonance amongst all interpretation trees that assume this note as rootdiss ctx: same asdiss rawbut scaled by the probability of hearing this note as root (weighted byton)
Dissthe final dissonance score, which is the sum of alldiss ctxThe 4 most likely interpretation trees (as judged by the algorithm) are shown below, where the top left node of the tree is the root node.
Code
============ Graph diss: Cmaj13#11 (tertian lydian) =====================
Iteration 1/1
0.00c: ton 0.1611, ton ctx: 0.0000, ton tgt: 0.1705, diss raw: 0.0748, diss ctx: 0.0748
400.00c: ton 0.1478, ton ctx: 0.0000, ton tgt: 0.1504, diss raw: 0.0724, diss ctx: 0.0718
700.00c: ton 0.1368, ton ctx: 0.0000, ton tgt: 0.1334, diss raw: 0.0605, diss ctx: 0.0606
1100.00c: ton 0.1324, ton ctx: 0.0000, ton tgt: 0.1270, diss raw: 0.0566, diss ctx: 0.0570
1400.00c: ton 0.1378, ton ctx: 0.0000, ton tgt: 0.1351, diss raw: 0.0529, diss ctx: 0.0530
1800.00c: ton 0.1340, ton ctx: 0.0000, ton tgt: 0.1296, diss raw: 0.0465, diss ctx: 0.0467
2100.00c: ton 0.1501, ton ctx: 0.0000, ton tgt: 0.1540, diss raw: 0.0470, diss ctx: 0.0467
Diss: 0.4107
2.5s: [
Dissonance {
dissonance: 0.4106800958248316,
tonicity_target: [
0.17051008893464303,
0.15043997138920753,
0.13344729429122867,
0.12696922247690193,
0.13506228978304868,
0.12957744307707025,
0.15399369004790817,
],
tonicity_context: [
0.1610662730343112,
0.1477587041992881,
0.13678682445859125,
0.13240932817405227,
0.1378075940872702,
0.13402268776620052,
0.15014858828028635,
],
},
]
Top 4 likelihood trees:
-> likelihood 1.1383 (complexity 0.3724):
C4
├── G4
├── B4
└── D5
├── E4
├── F#5
└── A5
-> likelihood 1.1304 (complexity 0.4305):
C4
├── E4
├── G4
│ ├── D5
│ ├── F#5
│ └── A5
└── B4
-> likelihood 1.0836 (complexity 0.4062):
E4
├── C4
│ ├── G4
│ ├── D5
│ └── A5
├── B4
└── F#5
-> likelihood 1.0677 (complexity 0.4090):
C4
├── E4
│ ├── B4
│ ├── F#5
│ └── A5
├── G4
└── D5
In Cmaj13#11, the algorithm identifies C as the first tonic candidate, followed by A, E, D, G, F# and B being the least likely tonic. This mostly agrees with my intuition, except that perhaps D (tonicity 0.1378) and G (0.1368) should be swapped as I would expect to see this chord in the context of G major more than D major/minor. Note that the "tonicity" score doesn't identify quality/tonality, it merely scores the rootedness of inividual notes, so the next most likely tonics A and E are to be seen as the relative minors of C and G, rather than the relative major.
The model is not as certain of the tonic as compared to say, the other simpler 4-adic chords in the test (this can be measured using the entropy of the tonicity scores). This is expected since this 7-adic chord can appear in many contexts.
While cultural entrainment will first assume that the key is G major because it contains all 7 notes of G major, this model is identifying the tonic/root as in the definition of "how many other notes are being heard relative to this note", not in the definition of the cultural sense of "key". C having the highest tonicity score agrees with how I would instictively choose to hear most notes relative to C if I had no prior knowledge of the key. This is identified as the lydian tonality in modern western music.
The second highest likelihood tree is an interpretation that I would use myself (Cmaj7 with D triad upper structure), so seeing it up high in what the algorithm thinks is likely, out of 6972 other trees it is considering, is a good sign.
Code
============ Graph diss: Cmin13 (tertian dorian) =====================
Iteration 1/1
0.00c: ton 0.1515, ton ctx: 0.0000, ton tgt: 0.1561, diss raw: 0.0697, diss ctx: 0.0693
300.00c: ton 0.1552, ton ctx: 0.0000, ton tgt: 0.1615, diss raw: 0.0787, diss ctx: 0.0784
700.00c: ton 0.1330, ton ctx: 0.0000, ton tgt: 0.1278, diss raw: 0.0575, diss ctx: 0.0579
1000.00c: ton 0.1407, ton ctx: 0.0000, ton tgt: 0.1395, diss raw: 0.0606, diss ctx: 0.0605
1400.00c: ton 0.1312, ton ctx: 0.0000, ton tgt: 0.1252, diss raw: 0.0500, diss ctx: 0.0505
1700.00c: ton 0.1532, ton ctx: 0.0000, ton tgt: 0.1587, diss raw: 0.0543, diss ctx: 0.0539
2100.00c: ton 0.1351, ton ctx: 0.0000, ton tgt: 0.1312, diss raw: 0.0418, diss ctx: 0.0419
Diss: 0.4125
2.5s: [
Dissonance {
dissonance: 0.4124988755294595,
tonicity_target: [
0.15610054068858686,
0.16153141105799676,
0.12783959082987867,
0.139466206563926,
0.12515187025164054,
0.15869158387278784,
0.13121879673518316,
],
tonicity_context: [
0.1514880294673888,
0.15519416731968377,
0.1330333416434903,
0.14071501631003436,
0.13124630393589354,
0.1532077273557646,
0.1351154139677446,
],
},
]
Top 4 likelihood trees:
-> likelihood 1.1415 (complexity 0.4248):
Eb4
├── C4
│ ├── G4
│ ├── D5
│ └── A5
├── Bb4
└── F5
-> likelihood 1.1192 (complexity 0.4348):
Eb4
├── G4
├── Bb4
│ ├── C4
│ ├── F5
│ └── A5
└── D5
-> likelihood 1.0885 (complexity 0.4303):
C4
├── Eb4
│ ├── Bb4
│ ├── F5
│ └── A5
├── G4
└── D5
-> likelihood 1.0855 (complexity 0.4686):
Bb4
├── C4
├── G4
│ ├── Eb4
│ ├── D5
│ └── A5
└── F5
In the Cm13 voicing in thirds, the algorithm identifies Eb, F, and C in a close first, second, and third place for likely roots. This is followed by Bb as moderately likely, then the rest have relatively low tonicity.
This voicing is assigned 0.0018 more dissonance than Cmaj13#11, which may not seem like a lot, but considering that the standard deviation for dissonance for 7-note chords is 0.065 for randomly generated sets of pitches (uniform distribution over log space hertz; see Distributions of dissonance scores), and that the major-minor-third dyadic complexity difference is 0.05, this value is already sufficient, considering that we are not comparing random pitches, but structured chords that are expected to have much less variance in dissonance scores.
I agree with the highest likelihood tree, except for its choice of root (I would rather see C as root instead). The algorithm being able to identify the stack of fifths in the tertian voicings is promising. The third most likely tree is also very sensible to me. Again, these are the top 4 trees out of 6972, so it will be rare to find agreeable interpretation trees if the likelihood algorithm's parameters are not tuned correctly.
Code
============ Graph diss: Cm11b5b9b13 (tertian locrian) =====================
Iteration 1/1
0.00c: ton 0.1374, ton ctx: 0.0000, ton tgt: 0.1347, diss raw: 0.0669, diss ctx: 0.0671
300.00c: ton 0.1473, ton ctx: 0.0000, ton tgt: 0.1497, diss raw: 0.0751, diss ctx: 0.0748
600.00c: ton 0.1470, ton ctx: 0.0000, ton tgt: 0.1489, diss raw: 0.0751, diss ctx: 0.0750
1000.00c: ton 0.1361, ton ctx: 0.0000, ton tgt: 0.1326, diss raw: 0.0583, diss ctx: 0.0586
1300.00c: ton 0.1374, ton ctx: 0.0000, ton tgt: 0.1344, diss raw: 0.0575, diss ctx: 0.0578
1700.00c: ton 0.1444, ton ctx: 0.0000, ton tgt: 0.1454, diss raw: 0.0513, diss ctx: 0.0511
2000.00c: ton 0.1504, ton ctx: 0.0000, ton tgt: 0.1543, diss raw: 0.0503, diss ctx: 0.0502
Diss: 0.4346
2.5s: [
Dissonance {
dissonance: 0.4346322369714205,
tonicity_target: [
0.13468621312165735,
0.14967456240377994,
0.148918367632673,
0.13260490097152786,
0.13440927681279385,
0.14537448446663281,
0.1543321945909347,
],
tonicity_context: [
0.1373643018809243,
0.14728349129240942,
0.14696953913240363,
0.13614985655411022,
0.13740405728089675,
0.14443239067821753,
0.15039636318103827,
],
},
]
Trees sorted by descending diss contribution:
-> contrib 0.0001 (complexity 0.5131, likelihood 1.0229):
Eb4
├── C4
├── Gb4
│ ├── Db5
│ ├── F5
│ └── Ab5
└── Bb4
-> contrib 0.0001 (complexity 0.4965, likelihood 1.0320):
Gb4
├── Eb4
├── Bb4
│ ├── C4
│ ├── F5
│ └── Ab5
└── Db5
-> contrib 0.0001 (complexity 0.4768, likelihood 1.0199):
Gb4
├── Eb4
├── Bb4
└── Db5
├── C4
├── F5
└── Ab5
-> contrib 0.0001 (complexity 0.5169, likelihood 0.9233):
Eb4
├── C4
├── Gb4
│ ├── Db5
│ │ └── Ab5
│ └── F5
└── Bb4
Finally, just for fun, I fed a chord voicing I would never play myself, or don't recall hearing, into the algorithm, just to see if what I can make sense of it aurally and instictively agrees with the algorithm. This Cm11b5b9b13 voicing is the locrian scale organized in thirds from C.
First, without looking at the results of the algorithm, my aural perception chooses to identify this as a weird rootless Ab dominant voicing with an added 4 (Db) for some reason. If I removed the Db, it would just be a Ab13(9) or something Bill Evans would play for a Cm7b5 or Ab7 chord. I would rank this as a big step up in perceived complexity from the previous two.
Now looking at the algorithm, it assigned the highest tonicity to Ab with a score of 0.15, even though Ab5 is the highest note in the voicing, and there is a slight bias coded in the likelihood algorithm to prefer lower notes as root! After that, Eb and Gb were close, F in the middle, followed by Db and C a tie, and Bb in last place. I would agree this could also be used in the context of a rootless voicing for Ebm6 or the #4 half diminished of the key of Gb major.
Of the three 7-adic chords so far, this scores the highest dissonance, which I agree with, scoring 0.0239 higher than Cmaj13#11, which is 0.36 standard deviations relative to the distribution of dissonance of random 7-note chords.
# Effect of context
Now I want to test if existing note tonciity context can have any impact on the algorithm's output.
For the same 3 voicings above, I tried choosing 3 different "keys" as context: the obvious choice, the related (relative minor/major), and the "wrong" choice. To denote a "key", I set the relative tonicity of that note to twice as high as the other notes.
Because of the smoothing of the tonicity context, the ton values will naturally be heavily skewed towards the context of the key, so the values we should be really looking at is ton tgt, which is the unsmoothed tonicity values that the algorithm outputs.
# Cmaj13#11 in the context of C, E, and F#
Code
============ Graph diss: Cmaj13#11 with no context =====================
Iteration 1/1
0.00c: ton 0.1611, ton ctx: 0.0000, ton tgt: 0.1705, diss raw: 0.0748, diss ctx: 0.0748
400.00c: ton 0.1478, ton ctx: 0.0000, ton tgt: 0.1504, diss raw: 0.0724, diss ctx: 0.0718
700.00c: ton 0.1368, ton ctx: 0.0000, ton tgt: 0.1334, diss raw: 0.0605, diss ctx: 0.0606
1100.00c: ton 0.1324, ton ctx: 0.0000, ton tgt: 0.1270, diss raw: 0.0566, diss ctx: 0.0570
1400.00c: ton 0.1378, ton ctx: 0.0000, ton tgt: 0.1351, diss raw: 0.0529, diss ctx: 0.0530
1800.00c: ton 0.1340, ton ctx: 0.0000, ton tgt: 0.1296, diss raw: 0.0465, diss ctx: 0.0467
2100.00c: ton 0.1501, ton ctx: 0.0000, ton tgt: 0.1540, diss raw: 0.0470, diss ctx: 0.0467
Diss: 0.4107
2.5s: [
Dissonance {
dissonance: 0.4106800958248316,
tonicity_target: [
0.17051008893464303,
0.15043997138920753,
0.13344729429122867,
0.12696922247690193,
0.13506228978304868,
0.12957744307707025,
0.15399369004790817,
],
tonicity_context: [
0.1610662730343112,
0.1477587041992881,
0.13678682445859125,
0.13240932817405227,
0.1378075940872702,
0.13402268776620052,
0.15014858828028635,
],
},
]
Top 4 likelihood trees:
-> likelihood 1.1383 (complexity 0.3724):
C4
├── G4
├── B4
└── D5
├── E4
├── F#5
└── A5
-> likelihood 1.1304 (complexity 0.4305):
C4
├── E4
├── G4
│ ├── D5
│ ├── F#5
│ └── A5
└── B4
-> likelihood 1.0836 (complexity 0.4062):
E4
├── C4
│ ├── G4
│ ├── D5
│ └── A5
├── B4
└── F#5
-> likelihood 1.0677 (complexity 0.4090):
C4
├── E4
│ ├── B4
│ ├── F#5
│ └── A5
├── G4
└── D5
============ Graph diss: Cmaj13#11 with C context =====================
Iteration 1/1
0.00c: ton 0.2953, ton ctx: 0.2000, ton tgt: 0.3196, diss raw: 0.1381, diss ctx: 0.2145
400.00c: ton 0.1233, ton ctx: 0.1000, ton tgt: 0.1224, diss raw: 0.0590, diss ctx: 0.0428
700.00c: ton 0.1152, ton ctx: 0.1000, ton tgt: 0.1100, diss raw: 0.0498, diss ctx: 0.0371
1100.00c: ton 0.1121, ton ctx: 0.1000, ton tgt: 0.1052, diss raw: 0.0468, diss ctx: 0.0354
1400.00c: ton 0.1159, ton ctx: 0.1000, ton tgt: 0.1110, diss raw: 0.0433, diss ctx: 0.0322
1800.00c: ton 0.1135, ton ctx: 0.1000, ton tgt: 0.1073, diss raw: 0.0384, diss ctx: 0.0288
2100.00c: ton 0.1247, ton ctx: 0.1000, ton tgt: 0.1246, diss raw: 0.0380, diss ctx: 0.0275
Diss: 0.4183
2.5s: [
Dissonance {
dissonance: 0.4182613180514423,
tonicity_target: [
0.3195704452117313,
0.12235629341951536,
0.11000728177445471,
0.10522785616115078,
0.11095436634387473,
0.10732210143270046,
0.12456165565657261,
],
tonicity_context: [
0.29531273089824234,
0.12327809690608087,
0.11523491937819669,
0.11212197643231357,
0.11585177597730857,
0.1134860035293925,
0.12471449687846554,
],
},
]
Top 4 likelihood trees:
-> likelihood 2.3942 (complexity 0.3724):
C4
├── G4
├── B4
└── D5
├── E4
├── F#5
└── A5
-> likelihood 2.3758 (complexity 0.4305):
C4
├── E4
├── G4
│ ├── D5
│ ├── F#5
│ └── A5
└── B4
-> likelihood 2.2478 (complexity 0.4090):
C4
├── E4
│ ├── B4
│ ├── F#5
│ └── A5
├── G4
└── D5
-> likelihood 2.2422 (complexity 0.3800):
C4
├── G4
│ ├── E4
│ ├── F#5
│ └── A5
├── B4
└── D5
============ Graph diss: Cmaj13#11 with E context =====================
Iteration 1/1
0.00c: ton 0.1370, ton ctx: 0.1000, ton tgt: 0.1434, diss raw: 0.0632, diss ctx: 0.0512
400.00c: ton 0.2575, ton ctx: 0.2000, ton tgt: 0.2615, diss raw: 0.1246, diss ctx: 0.1847
700.00c: ton 0.1199, ton ctx: 0.1000, ton tgt: 0.1172, diss raw: 0.0532, diss ctx: 0.0444
1100.00c: ton 0.1171, ton ctx: 0.1000, ton tgt: 0.1129, diss raw: 0.0503, diss ctx: 0.0424
1400.00c: ton 0.1205, ton ctx: 0.1000, ton tgt: 0.1181, diss raw: 0.0463, diss ctx: 0.0386
1800.00c: ton 0.1183, ton ctx: 0.1000, ton tgt: 0.1147, diss raw: 0.0412, diss ctx: 0.0346
2100.00c: ton 0.1297, ton ctx: 0.1000, ton tgt: 0.1323, diss raw: 0.0404, diss ctx: 0.0330
Diss: 0.4290
2.5s: [
Dissonance {
dissonance: 0.42902432502762405,
tonicity_target: [
0.14338778469618205,
0.261464182861242,
0.11717782934064233,
0.11290489748378715,
0.11811846540196741,
0.1146703448065773,
0.13227649540959843,
],
tonicity_context: [
0.13697636061142293,
0.25746686946416353,
0.1199052516043434,
0.11712219896199008,
0.12051790815110384,
0.11827207286619104,
0.1297393383407851,
],
},
]
Top 4 likelihood trees:
-> likelihood 2.2914 (complexity 0.4062):
E4
├── C4
│ ├── G4
│ ├── D5
│ └── A5
├── B4
└── F#5
-> likelihood 2.0637 (complexity 0.4146):
E4
├── C4
│ ├── G4
│ └── D5
│ └── A5
├── B4
└── F#5
-> likelihood 2.0611 (complexity 0.5019):
E4
├── C4
├── G4
│ ├── D5
│ ├── F#5
│ └── A5
└── B4
-> likelihood 2.0453 (complexity 0.4128):
E4
├── C4
│ ├── G4
│ │ └── A5
│ └── D5
├── B4
└── F#5
============ Graph diss: Cmaj13#11 with F# context =====================
Iteration 1/1
0.00c: ton 0.1449, ton ctx: 0.1000, ton tgt: 0.1556, diss raw: 0.0683, diss ctx: 0.0606
400.00c: ton 0.1339, ton ctx: 0.1000, ton tgt: 0.1386, diss raw: 0.0667, diss ctx: 0.0595
700.00c: ton 0.1242, ton ctx: 0.1000, ton tgt: 0.1238, diss raw: 0.0561, diss ctx: 0.0508
1100.00c: ton 0.1203, ton ctx: 0.1000, ton tgt: 0.1178, diss raw: 0.0525, diss ctx: 0.0481
1400.00c: ton 0.1251, ton ctx: 0.1000, ton tgt: 0.1251, diss raw: 0.0490, diss ctx: 0.0444
1800.00c: ton 0.2147, ton ctx: 0.2000, ton tgt: 0.1958, diss raw: 0.0704, diss ctx: 0.0998
2100.00c: ton 0.1368, ton ctx: 0.1000, ton tgt: 0.1432, diss raw: 0.0437, diss ctx: 0.0389
Diss: 0.4021
2.5s: [
Dissonance {
dissonance: 0.4021356166590806,
tonicity_target: [
0.15562932371374713,
0.13864037682523703,
0.12380036760540818,
0.11782193587320959,
0.12514485784587187,
0.19578675729285738,
0.14317638084367082,
],
tonicity_context: [
0.14494953889991966,
0.13388427151143703,
0.12421865355744773,
0.12032477207587648,
0.12509434903813688,
0.21468974619274633,
0.13683866872443598,
],
},
]
Top 4 likelihood trees:
-> likelihood 1.5115 (complexity 0.3776):
F#5
├── C4
│ ├── G4
│ ├── B4
│ └── D5
├── E4
└── A5
-> likelihood 1.4853 (complexity 0.3612):
F#5
├── C4
│ ├── G4
│ ├── B4
│ └── A5
├── E4
└── D5
-> likelihood 1.4422 (complexity 0.4502):
F#5
├── C4
├── G4
└── D5
├── E4
├── B4
└── A5
-> likelihood 1.4173 (complexity 0.3649):
F#5
├── C4
├── E4
└── G4
├── B4
├── D5
└── A5
Compared to the context-free heuristic initialization from the previous test, the context of the key of C greatly increased the perception of C as root in ton tgt. C now has a target tonicity of 0.3196, up from 0.1705 — an increase of 87%. For reference, uniform tonicity is . The top 4 likelihood interpretation trees all have C as the root, which is expected since global tonicity context affects likelihood.
Similarly, the context of E increased the perception of E as root from 0.1584 to 0.2615, this time an increase of 65%. This increase is not as much as C, since the algorithm has shown a natural bias towards the root of C in the context-free test. Another interesting thing to note is that the tonicity of A is higher in the context of E than in the context of C.
Finally, the context of F# applied to Cmaj13#11 yielded the least increase in tonicity: from 0.1296 to 0.1958, which is 51%. After the third iteration, the algorithm is to identify that it is highly improbable that the key is still F#:
Code
============ Graph diss: Cmaj13#11 with F# context =====================
Iteration 1/5
0.00c: ton 0.1449, ton ctx: 0.1000, ton tgt: 0.1556, diss raw: NaN, diss ctx: NaN
400.00c: ton 0.1339, ton ctx: 0.1000, ton tgt: 0.1386, diss raw: NaN, diss ctx: NaN
700.00c: ton 0.1242, ton ctx: 0.1000, ton tgt: 0.1238, diss raw: NaN, diss ctx: NaN
1100.00c: ton 0.1203, ton ctx: 0.1000, ton tgt: 0.1178, diss raw: NaN, diss ctx: NaN
1400.00c: ton 0.1251, ton ctx: 0.1000, ton tgt: 0.1251, diss raw: NaN, diss ctx: NaN
1800.00c: ton 0.2147, ton ctx: 0.2000, ton tgt: 0.1958, diss raw: NaN, diss ctx: NaN
2100.00c: ton 0.1368, ton ctx: 0.1000, ton tgt: 0.1432, diss raw: NaN, diss ctx: NaN
Diss: 0.4021
Iteration 2/5
0.00c: ton 0.1652, ton ctx: 0.1449, ton tgt: 0.1760, diss raw: NaN, diss ctx: NaN
400.00c: ton 0.1381, ton ctx: 0.1339, ton tgt: 0.1404, diss raw: NaN, diss ctx: NaN
700.00c: ton 0.1200, ton ctx: 0.1242, ton tgt: 0.1177, diss raw: NaN, diss ctx: NaN
1100.00c: ton 0.1139, ton ctx: 0.1203, ton tgt: 0.1104, diss raw: NaN, diss ctx: NaN
1400.00c: ton 0.1212, ton ctx: 0.1251, ton tgt: 0.1192, diss raw: NaN, diss ctx: NaN
1800.00c: ton 0.1990, ton ctx: 0.2147, ton tgt: 0.1906, diss raw: NaN, diss ctx: NaN
2100.00c: ton 0.1427, ton ctx: 0.1368, ton tgt: 0.1458, diss raw: NaN, diss ctx: NaN
Diss: 0.4037
Iteration 3/5
0.00c: ton 0.1977, ton ctx: 0.1652, ton tgt: 0.2151, diss raw: NaN, diss ctx: NaN
400.00c: ton 0.1403, ton ctx: 0.1381, ton tgt: 0.1415, diss raw: NaN, diss ctx: NaN
700.00c: ton 0.1150, ton ctx: 0.1200, ton tgt: 0.1123, diss raw: NaN, diss ctx: NaN
1100.00c: ton 0.1080, ton ctx: 0.1139, ton tgt: 0.1048, diss raw: NaN, diss ctx: NaN
1400.00c: ton 0.1164, ton ctx: 0.1212, ton tgt: 0.1138, diss raw: NaN, diss ctx: NaN
1800.00c: ton 0.1774, ton ctx: 0.1990, ton tgt: 0.1659, diss raw: NaN, diss ctx: NaN
2100.00c: ton 0.1453, ton ctx: 0.1427, ton tgt: 0.1466, diss raw: NaN, diss ctx: NaN
Diss: 0.4068
Iteration 4/5
0.00c: ton 0.2458, ton ctx: 0.1977, ton tgt: 0.2716, diss raw: NaN, diss ctx: NaN
400.00c: ton 0.1389, ton ctx: 0.1403, ton tgt: 0.1382, diss raw: NaN, diss ctx: NaN
700.00c: ton 0.1086, ton ctx: 0.1150, ton tgt: 0.1052, diss raw: NaN, diss ctx: NaN
1100.00c: ton 0.1017, ton ctx: 0.1080, ton tgt: 0.0984, diss raw: NaN, diss ctx: NaN
1400.00c: ton 0.1099, ton ctx: 0.1164, ton tgt: 0.1065, diss raw: NaN, diss ctx: NaN
1800.00c: ton 0.1522, ton ctx: 0.1774, ton tgt: 0.1387, diss raw: NaN, diss ctx: NaN
2100.00c: ton 0.1428, ton ctx: 0.1453, ton tgt: 0.1414, diss raw: NaN, diss ctx: NaN
Diss: 0.4116
Iteration 5/5
0.00c: ton 0.2851, ton ctx: 0.2458, ton tgt: 0.3061, diss raw: NaN, diss ctx: NaN
400.00c: ton 0.1376, ton ctx: 0.1389, ton tgt: 0.1369, diss raw: NaN, diss ctx: NaN
700.00c: ton 0.1044, ton ctx: 0.1086, ton tgt: 0.1021, diss raw: NaN, diss ctx: NaN
1100.00c: ton 0.0980, ton ctx: 0.1017, ton tgt: 0.0960, diss raw: NaN, diss ctx: NaN
1400.00c: ton 0.1054, ton ctx: 0.1099, ton tgt: 0.1030, diss raw: NaN, diss ctx: NaN
1800.00c: ton 0.1306, ton ctx: 0.1522, ton tgt: 0.1190, diss raw: NaN, diss ctx: NaN
2100.00c: ton 0.1390, ton ctx: 0.1428, ton tgt: 0.1369, diss raw: NaN, diss ctx: NaN
Diss: 0.4159
Similar tests have been done for Cm13 with roots C (expected), Eb (relative), and A (wildcard):
Code
============ Graph diss: Cmin13 with no context =====================
Iteration 1/1
0.00c: ton 0.2687, ton ctx: 0.2000, ton tgt: 0.2787, diss raw: 0.1228, diss ctx: 0.1847
300.00c: ton 0.1319, ton ctx: 0.1000, ton tgt: 0.1357, diss raw: 0.0663, diss ctx: 0.0522
700.00c: ton 0.1159, ton ctx: 0.1000, ton tgt: 0.1110, diss raw: 0.0498, diss ctx: 0.0408
1000.00c: ton 0.1211, ton ctx: 0.1000, ton tgt: 0.1191, diss raw: 0.0516, diss ctx: 0.0416
1400.00c: ton 0.1144, ton ctx: 0.1000, ton tgt: 0.1087, diss raw: 0.0432, diss ctx: 0.0356
1700.00c: ton 0.1304, ton ctx: 0.1000, ton tgt: 0.1333, diss raw: 0.0454, diss ctx: 0.0358
2100.00c: ton 0.1175, ton ctx: 0.1000, ton tgt: 0.1135, diss raw: 0.0360, diss ctx: 0.0293
Diss: 0.4200
2.5s: [
Dissonance {
dissonance: 0.4200195039557328,
tonicity_target: [
0.2786830556993533,
0.13566726936887682,
0.11103331161766217,
0.11905318744640023,
0.10872970627517889,
0.13329465359007964,
0.11353881600245201,
],
tonicity_context: [
0.26868189258080083,
0.13194782252521006,
0.11590319473617827,
0.12112671277115625,
0.1144028069111181,
0.13040248671512056,
0.11753508376041588,
],
},
]
Top 4 likelihood trees:
-> likelihood 2.3013 (complexity 0.4302):
C4
├── Eb4
│ ├── Bb4
│ ├── F5
│ └── A5
├── G4
└── D5
-> likelihood 2.2048 (complexity 0.4154):
C4
├── Eb4
│ ├── Bb4
│ ├── D5
│ └── F5
├── G4
└── A5
-> likelihood 2.0830 (complexity 0.4189):
C4
├── Eb4
├── G4
└── D5
├── Bb4
├── F5
└── A5
-> likelihood 2.0745 (complexity 0.4325):
C4
├── Eb4
│ ├── Bb4
│ │ └── F5
│ └── A5
├── G4
└── D5
============ Graph diss: Cmin13 with C context =====================
Iteration 1/1
0.00c: ton 0.2687, ton ctx: 0.2000, ton tgt: 0.2787, diss raw: 0.1228, diss ctx: 0.1847
300.00c: ton 0.1319, ton ctx: 0.1000, ton tgt: 0.1357, diss raw: 0.0663, diss ctx: 0.0522
700.00c: ton 0.1159, ton ctx: 0.1000, ton tgt: 0.1110, diss raw: 0.0498, diss ctx: 0.0408
1000.00c: ton 0.1211, ton ctx: 0.1000, ton tgt: 0.1191, diss raw: 0.0516, diss ctx: 0.0416
1400.00c: ton 0.1144, ton ctx: 0.1000, ton tgt: 0.1087, diss raw: 0.0432, diss ctx: 0.0356
1700.00c: ton 0.1304, ton ctx: 0.1000, ton tgt: 0.1333, diss raw: 0.0454, diss ctx: 0.0358
2100.00c: ton 0.1175, ton ctx: 0.1000, ton tgt: 0.1135, diss raw: 0.0360, diss ctx: 0.0293
Diss: 0.4200
2.5s: [
Dissonance {
dissonance: 0.4200195039557328,
tonicity_target: [
0.2786830556993533,
0.13566726936887682,
0.11103331161766217,
0.11905318744640023,
0.10872970627517889,
0.13329465359007964,
0.11353881600245201,
],
tonicity_context: [
0.26868189258080083,
0.13194782252521006,
0.11590319473617827,
0.12112671277115625,
0.1144028069111181,
0.13040248671512056,
0.11753508376041588,
],
},
]
Top 4 likelihood trees:
-> likelihood 2.3013 (complexity 0.4302):
C4
├── Eb4
│ ├── Bb4
│ ├── F5
│ └── A5
├── G4
└── D5
-> likelihood 2.2048 (complexity 0.4154):
C4
├── Eb4
│ ├── Bb4
│ ├── D5
│ └── F5
├── G4
└── A5
-> likelihood 2.0830 (complexity 0.4189):
C4
├── Eb4
├── G4
└── D5
├── Bb4
├── F5
└── A5
-> likelihood 2.0745 (complexity 0.4325):
C4
├── Eb4
│ ├── Bb4
│ │ └── F5
│ └── A5
├── G4
└── D5
============ Graph diss: Cmin13 with Eb context =====================
Iteration 1/1
0.00c: ton 0.1273, ton ctx: 0.1000, ton tgt: 0.1286, diss raw: 0.0577, diss ctx: 0.0443
300.00c: ton 0.2788, ton ctx: 0.2000, ton tgt: 0.2942, diss raw: 0.1418, diss ctx: 0.2161
700.00c: ton 0.1144, ton ctx: 0.1000, ton tgt: 0.1087, diss raw: 0.0489, diss ctx: 0.0390
1000.00c: ton 0.1205, ton ctx: 0.1000, ton tgt: 0.1181, diss raw: 0.0514, diss ctx: 0.0401
1400.00c: ton 0.1131, ton ctx: 0.1000, ton tgt: 0.1067, diss raw: 0.0426, diss ctx: 0.0342
1700.00c: ton 0.1297, ton ctx: 0.1000, ton tgt: 0.1322, diss raw: 0.0453, diss ctx: 0.0346
2100.00c: ton 0.1162, ton ctx: 0.1000, ton tgt: 0.1115, diss raw: 0.0355, diss ctx: 0.0281
Diss: 0.4362
2.5s: [
Dissonance {
dissonance: 0.4362337172015992,
tonicity_target: [
0.12856377639645253,
0.2941859626917517,
0.10874937635193714,
0.11810250286147113,
0.10671220597712781,
0.13219852031374138,
0.1114876554075247,
],
tonicity_context: [
0.12732116440167177,
0.2787792701460738,
0.1144156184561954,
0.12050751140432708,
0.11308876546989254,
0.12968855147971733,
0.11619911864212219,
],
},
]
Top 4 likelihood trees:
-> likelihood 2.4048 (complexity 0.4248):
Eb4
├── C4
│ ├── G4
│ ├── D5
│ └── A5
├── Bb4
└── F5
-> likelihood 2.3543 (complexity 0.4348):
Eb4
├── G4
├── Bb4
│ ├── C4
│ ├── F5
│ └── A5
└── D5
-> likelihood 2.2157 (complexity 0.4557):
Eb4
├── C4
├── Bb4
│ ├── G4
│ ├── F5
│ └── A5
└── D5
-> likelihood 2.2013 (complexity 0.4489):
Eb4
├── G4
├── Bb4
└── D5
├── C4
├── F5
└── A5
============ Graph diss: Cmin13 with A context =====================
Iteration 1/1
0.00c: ton 0.1371, ton ctx: 0.1000, ton tgt: 0.1435, diss raw: 0.0641, diss ctx: 0.0568
300.00c: ton 0.1400, ton ctx: 0.1000, ton tgt: 0.1480, diss raw: 0.0720, diss ctx: 0.0637
700.00c: ton 0.1209, ton ctx: 0.1000, ton tgt: 0.1187, diss raw: 0.0533, diss ctx: 0.0486
1000.00c: ton 0.1275, ton ctx: 0.1000, ton tgt: 0.1288, diss raw: 0.0560, diss ctx: 0.0502
1400.00c: ton 0.1192, ton ctx: 0.1000, ton tgt: 0.1161, diss raw: 0.0463, diss ctx: 0.0425
1700.00c: ton 0.1385, ton ctx: 0.1000, ton tgt: 0.1458, diss raw: 0.0498, diss ctx: 0.0441
2100.00c: ton 0.2169, ton ctx: 0.2000, ton tgt: 0.1992, diss raw: 0.0634, diss ctx: 0.0900
Diss: 0.3959
2.5s: [
Dissonance {
dissonance: 0.3959484373831218,
tonicity_target: [
0.14353592251710454,
0.14795961380370812,
0.11866017810292628,
0.12878633373257203,
0.11609699613619981,
0.14578645231225407,
0.1991745033952327,
],
tonicity_context: [
0.1370728459680263,
0.13995409147733298,
0.12087073731250997,
0.12746612079300101,
0.11920128163563411,
0.1385386645448045,
0.2168962582686912,
],
},
]
Top 4 likelihood trees:
-> likelihood 1.4833 (complexity 0.3332):
A5
├── C4
│ ├── G4
│ ├── Bb4
│ └── D5
├── Eb4
└── F5
-> likelihood 1.4828 (complexity 0.2792):
A5
├── C4
├── Eb4
│ ├── Bb4
│ ├── D5
│ └── F5
└── G4
-> likelihood 1.4764 (complexity 0.3550):
A5
├── C4
├── Eb4
│ ├── G4
│ ├── Bb4
│ └── D5
└── F5
-> likelihood 1.4047 (complexity 0.3692):
A5
├── Eb4
├── G4
└── Bb4
├── C4
├── D5
└── F5
It is especially interesting that this particular voicing of Cm13 has two stable keys. Both C and Eb are equally possible keys that this voicing can live in, so the algorithm almost equally stabilizes both keys (with a slight preference for Eb). The context of the wildcard key A is again quickly rejected. It's also interesting to note that the perceived dissonance is lower for the context of C compared to Eb, even though the likelihood of the root Eb is slighly higher.
Finally, for Cm11b5b9b13 with roots Ab (expected domaintn), Eb (subdominant minor), and C (wildcard), we see the same pattern:
Code
============ Graph diss: Cm11b5b9b13 with no context =====================
Iteration 1/1
0.00c: ton 0.1203, ton ctx: 0.1000, ton tgt: 0.1178, diss raw: 0.0585, diss ctx: 0.0487
300.00c: ton 0.1284, ton ctx: 0.1000, ton tgt: 0.1302, diss raw: 0.0653, diss ctx: 0.0533
600.00c: ton 0.1276, ton ctx: 0.1000, ton tgt: 0.1289, diss raw: 0.0650, diss ctx: 0.0531
1000.00c: ton 0.1190, ton ctx: 0.1000, ton tgt: 0.1159, diss raw: 0.0509, diss ctx: 0.0425
1300.00c: ton 0.1197, ton ctx: 0.1000, ton tgt: 0.1169, diss raw: 0.0500, diss ctx: 0.0417
1700.00c: ton 0.1260, ton ctx: 0.1000, ton tgt: 0.1265, diss raw: 0.0446, diss ctx: 0.0366
2000.00c: ton 0.2590, ton ctx: 0.2000, ton tgt: 0.2638, diss raw: 0.0857, diss ctx: 0.1274
Diss: 0.4033
2.5s: [
Dissonance {
dissonance: 0.4032973304934846,
tonicity_target: [
0.11781704377565472,
0.1302038795933526,
0.12893747214857532,
0.11585221311836284,
0.11689462887936515,
0.1265255565785356,
0.26376920590615327,
],
tonicity_context: [
0.12032158574726606,
0.12838939897427423,
0.12756456050187293,
0.11904184917861937,
0.11972079703813973,
0.12599362789044755,
0.2589681806693801,
],
},
]
Top 4 likelihood trees:
-> likelihood 2.1619 (complexity 0.3396):
Ab5
├── C4
├── Eb4
└── Bb4
├── Gb4
├── Db5
└── F5
-> likelihood 2.0730 (complexity 0.3140):
Ab5
├── C4
├── Eb4
│ ├── Gb4
│ ├── Db5
│ └── F5
└── Bb4
-> likelihood 2.0612 (complexity 0.3312):
Ab5
├── C4
├── Eb4
└── Bb4
├── Gb4
│ └── Db5
└── F5
-> likelihood 2.0578 (complexity 0.3428):
Ab5
├── Eb4
├── Gb4
└── Bb4
├── C4
├── Db5
└── F5
============ Graph diss: Cm11b5b9b13 with Ab context =====================
Iteration 1/1
0.00c: ton 0.1203, ton ctx: 0.1000, ton tgt: 0.1178, diss raw: 0.0585, diss ctx: 0.0487
300.00c: ton 0.1284, ton ctx: 0.1000, ton tgt: 0.1302, diss raw: 0.0653, diss ctx: 0.0533
600.00c: ton 0.1276, ton ctx: 0.1000, ton tgt: 0.1289, diss raw: 0.0650, diss ctx: 0.0531
1000.00c: ton 0.1190, ton ctx: 0.1000, ton tgt: 0.1159, diss raw: 0.0509, diss ctx: 0.0425
1300.00c: ton 0.1197, ton ctx: 0.1000, ton tgt: 0.1169, diss raw: 0.0500, diss ctx: 0.0417
1700.00c: ton 0.1260, ton ctx: 0.1000, ton tgt: 0.1265, diss raw: 0.0446, diss ctx: 0.0366
2000.00c: ton 0.2590, ton ctx: 0.2000, ton tgt: 0.2638, diss raw: 0.0857, diss ctx: 0.1274
Diss: 0.4033
2.5s: [
Dissonance {
dissonance: 0.4032973304934846,
tonicity_target: [
0.11781704377565472,
0.1302038795933526,
0.12893747214857532,
0.11585221311836284,
0.11689462887936515,
0.1265255565785356,
0.26376920590615327,
],
tonicity_context: [
0.12032158574726606,
0.12838939897427423,
0.12756456050187293,
0.11904184917861937,
0.11972079703813973,
0.12599362789044755,
0.2589681806693801,
],
},
]
Top 4 likelihood trees:
-> likelihood 2.1619 (complexity 0.3396):
Ab5
├── C4
├── Eb4
└── Bb4
├── Gb4
├── Db5
└── F5
-> likelihood 2.0730 (complexity 0.3140):
Ab5
├── C4
├── Eb4
│ ├── Gb4
│ ├── Db5
│ └── F5
└── Bb4
-> likelihood 2.0612 (complexity 0.3312):
Ab5
├── C4
├── Eb4
└── Bb4
├── Gb4
│ └── Db5
└── F5
-> likelihood 2.0578 (complexity 0.3428):
Ab5
├── Eb4
├── Gb4
└── Bb4
├── C4
├── Db5
└── F5
============ Graph diss: Cm11b5b9b13 with Eb context =====================
Iteration 1/1
0.00c: ton 0.1199, ton ctx: 0.1000, ton tgt: 0.1172, diss raw: 0.0584, diss ctx: 0.0489
300.00c: ton 0.2571, ton ctx: 0.2000, ton tgt: 0.2609, diss raw: 0.1295, diss ctx: 0.1921
600.00c: ton 0.1274, ton ctx: 0.1000, ton tgt: 0.1288, diss raw: 0.0651, diss ctx: 0.0535
1000.00c: ton 0.1198, ton ctx: 0.1000, ton tgt: 0.1171, diss raw: 0.0515, diss ctx: 0.0431
1300.00c: ton 0.1200, ton ctx: 0.1000, ton tgt: 0.1172, diss raw: 0.0502, diss ctx: 0.0420
1700.00c: ton 0.1261, ton ctx: 0.1000, ton tgt: 0.1267, diss raw: 0.0448, diss ctx: 0.0369
2000.00c: ton 0.1296, ton ctx: 0.1000, ton tgt: 0.1321, diss raw: 0.0431, diss ctx: 0.0353
Diss: 0.4518
2.5s: [
Dissonance {
dissonance: 0.45180446473714037,
tonicity_target: [
0.11718028295585448,
0.2608952295980413,
0.12875851095070154,
0.11709117576217763,
0.11724812177722325,
0.1267125433812141,
0.1321141355747902,
],
tonicity_context: [
0.11990684969683033,
0.2570962979372645,
0.12744799921531197,
0.11984881226044641,
0.11995103458378602,
0.12611541642644858,
0.12963358987991225,
],
},
]
Top 4 likelihood trees:
-> likelihood 2.1629 (complexity 0.5131):
Eb4
├── C4
├── Gb4
│ ├── Db5
│ ├── F5
│ └── Ab5
└── Bb4
-> likelihood 2.0880 (complexity 0.4442):
Eb4
├── C4
│ ├── Gb4
│ ├── Db5
│ └── Ab5
├── Bb4
└── F5
-> likelihood 1.9767 (complexity 0.4908):
Eb4
├── C4
├── Gb4
└── Bb4
├── Db5
├── F5
└── Ab5
-> likelihood 1.9658 (complexity 0.4221):
Eb4
├── C4
├── Bb4
└── F5
├── Gb4
├── Db5
└── Ab5
============ Graph diss: Cm11b5b9b13 with C context =====================
Iteration 1/1
0.00c: ton 0.2299, ton ctx: 0.2000, ton tgt: 0.2192, diss raw: 0.1084, diss ctx: 0.1558
300.00c: ton 0.1314, ton ctx: 0.1000, ton tgt: 0.1349, diss raw: 0.0679, diss ctx: 0.0592
600.00c: ton 0.1307, ton ctx: 0.1000, ton tgt: 0.1337, diss raw: 0.0675, diss ctx: 0.0590
1000.00c: ton 0.1223, ton ctx: 0.1000, ton tgt: 0.1208, diss raw: 0.0530, diss ctx: 0.0471
1300.00c: ton 0.1233, ton ctx: 0.1000, ton tgt: 0.1224, diss raw: 0.0523, diss ctx: 0.0464
1700.00c: ton 0.1289, ton ctx: 0.1000, ton tgt: 0.1310, diss raw: 0.0461, diss ctx: 0.0403
2000.00c: ton 0.1335, ton ctx: 0.1000, ton tgt: 0.1381, diss raw: 0.0450, diss ctx: 0.0392
Diss: 0.4470
2.5s: [
Dissonance {
dissonance: 0.44700510860341214,
tonicity_target: [
0.21920410428982454,
0.13485036944613094,
0.13368375490363213,
0.12082277199636758,
0.12240207428799665,
0.13096999695694417,
0.13806692811910296,
],
tonicity_context: [
0.22994196916753096,
0.1314157579932454,
0.13065591678962304,
0.12227928134061625,
0.12330791497275374,
0.12888838773059522,
0.1335107720056354,
],
},
]
Top 4 likelihood trees:
-> likelihood 1.5751 (complexity 0.4967):
C4
├── Eb4
│ ├── Bb4
│ ├── F5
│ └── Ab5
├── Gb4
└── Db5
-> likelihood 1.5695 (complexity 0.5000):
C4
├── Eb4
├── Gb4
└── Db5
├── Bb4
├── F5
└── Ab5
-> likelihood 1.5558 (complexity 0.4694):
C4
├── Eb4
│ ├── Bb4
│ ├── Db5
│ └── F5
├── Gb4
└── Ab5
-> likelihood 1.5485 (complexity 0.4726):
C4
├── Eb4
├── Gb4
│ ├── Bb4
│ ├── Db5
│ └── F5
└── Ab5
Note
To test this model thoroughly and with real-time constraints (where a maximum of 800 trees are scanned for tonicity updates and 4000 trees for detemperament candidate selection), I highly recommend playing around with the visualizer — for 12EDO, it works with MIDI input through the browser. It takes a bit of setup, but I will be happy to assist if necessary.
# Appendix
# Distributions of dissonance scores
I generated 1000 random 2-note to 8-note chords each, with notes uniformly distributed in the range C3 to C6.
Code
Dissonance stats for 2 random notes in C3 - C6:
Min: 0.06509579095729916
Max: 0.9999756866320135
Mean: 0.42967363163119876
Std: 0.2031251603048741
# Number of samples = 1000
# Min = 650
# Max = 9999
#
# Mean = 4296.231000000006
# Standard deviation = 2031.2502050803603
# Variance = 4125977.395639006
#
# Each ∎ is a count of 3
#
650 .. 1585 [ 79 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
1585 .. 2520 [ 143 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
2520 .. 3455 [ 171 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3455 .. 4390 [ 137 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4390 .. 5325 [ 167 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5325 .. 6260 [ 142 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
6260 .. 7195 [ 80 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
7195 .. 8130 [ 34 ]: ∎∎∎∎∎∎∎∎∎∎∎
8130 .. 9065 [ 19 ]: ∎∎∎∎∎∎
9065 .. 10000 [ 28 ]: ∎∎∎∎∎∎∎∎∎
Dissonance stats for 3 random notes in C3 - C6:
Min: 0.2050611819813634
Max: 0.9608329132223163
Mean: 0.42742535292649436
Std: 0.12394500118536399
# Number of samples = 1000
# Min = 2050
# Max = 9608
#
# Mean = 4273.740999999993
# Standard deviation = 1239.4534964729407
# Variance = 1536244.969918998
#
# Each ∎ is a count of 5
#
2050 .. 2806 [ 93 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
2806 .. 3562 [ 224 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3562 .. 4318 [ 262 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4318 .. 5074 [ 170 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5074 .. 5830 [ 128 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5830 .. 6586 [ 78 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
6586 .. 7342 [ 25 ]: ∎∎∎∎∎
7342 .. 8098 [ 13 ]: ∎∎
8098 .. 8854 [ 6 ]: ∎
8854 .. 9610 [ 1 ]:
Dissonance stats for 4 random notes in C3 - C6:
Min: 0.24631054643729602
Max: 0.7938273753576092
Mean: 0.434234963083168
Std: 0.09108240292315453
# Number of samples = 1000
# Min = 2463
# Max = 7938
#
# Mean = 4341.848000000003
# Standard deviation = 910.8446381771157
# Variance = 829637.9548960008
#
# Each ∎ is a count of 5
#
2463 .. 3011 [ 30 ]: ∎∎∎∎∎∎
3011 .. 3559 [ 170 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3559 .. 4107 [ 266 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4107 .. 4655 [ 208 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4655 .. 5203 [ 162 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5203 .. 5751 [ 78 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5751 .. 6299 [ 47 ]: ∎∎∎∎∎∎∎∎∎
6299 .. 6847 [ 25 ]: ∎∎∎∎∎
6847 .. 7395 [ 11 ]: ∎∎
7395 .. 7943 [ 3 ]:
Dissonance stats for 5 random notes in C3 - C6:
Min: 0.2575482308937836
Max: 0.7216396909533023
Mean: 0.4297081842124831
Std: 0.07481909472979106
# Number of samples = 1000
# Min = 2575
# Max = 7216
#
# Mean = 4296.593000000006
# Standard deviation = 748.1831175260497
# Variance = 559777.9773509987
#
# Each ∎ is a count of 5
#
2575 .. 3039 [ 19 ]: ∎∎∎
3039 .. 3503 [ 107 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3503 .. 3967 [ 253 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3967 .. 4431 [ 229 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4431 .. 4895 [ 199 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4895 .. 5359 [ 102 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5359 .. 5823 [ 53 ]: ∎∎∎∎∎∎∎∎∎∎
5823 .. 6287 [ 23 ]: ∎∎∎∎
6287 .. 6751 [ 8 ]: ∎
6751 .. 7215 [ 7 ]: ∎
Dissonance stats for 6 random notes in C3 - C6:
Min: 0.29629362096951933
Max: 0.7345926011935215
Mean: 0.44078887081154344
Std: 0.06924131800880022
# Number of samples = 1000
# Min = 2962
# Max = 7345
#
# Mean = 4407.395999999996
# Standard deviation = 692.4064118593933
# Variance = 479426.6391839998
#
# Each ∎ is a count of 5
#
2962 .. 3400 [ 55 ]: ∎∎∎∎∎∎∎∎∎∎∎
3400 .. 3838 [ 147 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3838 .. 4276 [ 262 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4276 .. 4714 [ 236 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4714 .. 5152 [ 163 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5152 .. 5590 [ 82 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5590 .. 6028 [ 32 ]: ∎∎∎∎∎∎
6028 .. 6466 [ 12 ]: ∎∎
6466 .. 6904 [ 8 ]: ∎
6904 .. 7342 [ 3 ]:
Dissonance stats for 7 random notes in C3 - C6:
Min: 0.271249203643672
Max: 0.6722409856590877
Mean: 0.4386986066050516
Std: 0.06528599900542552
# Number of samples = 1000
# Min = 2712
# Max = 6722
#
# Mean = 4386.494000000003
# Standard deviation = 652.8571788408237
# Variance = 426222.49596399924
#
# Each ∎ is a count of 5
#
2712 .. 3113 [ 4 ]:
3113 .. 3514 [ 67 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎
3514 .. 3915 [ 177 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3915 .. 4316 [ 259 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4316 .. 4717 [ 217 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4717 .. 5118 [ 126 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5118 .. 5519 [ 88 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5519 .. 5920 [ 44 ]: ∎∎∎∎∎∎∎∎
5920 .. 6321 [ 13 ]: ∎∎
6321 .. 6722 [ 5 ]: ∎
Dissonance stats for 8 random notes in C3 - C6:
Min: 0.28264162163078616
Max: 0.6697712234145415
Mean: 0.4362732310644634
Std: 0.06212190731355506
# Number of samples = 1000
# Min = 2826
# Max = 6697
#
# Mean = 4362.244999999997
# Standard deviation = 621.2306004818175
# Variance = 385927.45897499955
#
# Each ∎ is a count of 4
#
2826 .. 3213 [ 9 ]: ∎∎
3213 .. 3600 [ 92 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3600 .. 3987 [ 194 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3987 .. 4374 [ 241 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4374 .. 4761 [ 221 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4761 .. 5148 [ 125 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5148 .. 5535 [ 76 ]: ∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5535 .. 5922 [ 30 ]: ∎∎∎∎∎∎∎
5922 .. 6309 [ 8 ]: ∎∎
6309 .. 6696 [ 4 ]: ∎
Judging from the above janky histograms and stats, this algorithm's dissonance scores seem to be slightly fat-tailed (leptokurtic), but generally well-behaved. Most random chords fall within the 0.3 to 0.6 dissonance range, with very few chords being extremely consonant (<0.2) or extremely dissonant (>0.8). The mean hovers around 0.43-0.44 for all chord sizes, but the standard deviation decreases as there are more notes, which is expected since the more randomly chosen notes there are, the higher probability that the final chord is unstructured and dissonant.
# Thanks for reading!
If you have made it until here, I sincerely thank you and appreciate your interest! Feel free to reach out over Discord (@euwbah), Instagram (@euwbah), or email (euwbah [a𝐭] ġmаíḷ [ɗօt] ċοm).
If you wish to support my work & research, you may share this article, star this repository on GitHub, subscribe to my YouTube channel, or consider sponsoring me.

Thank you!